Проблема изоморфизма пересечения языковых пар
Итак, мы определили, что представление на языке UNL позволяет полностью сохранить смысл (поскольку лексическими единицами являются однозначные обозначения понятий) и обеспечивает независимость изоморфизма пересечения языковых пар от порядка слов в предложениях. Тем не менее, осталась и усугубилась проблема нарушения изоморфизма, вызванного различием форм одного и того же слова в разных предложениях. Действительно, концепт в языке UNL, не меняет своей формы, с каким бы другим концептом он ни был связан. В то же время, одно и то же слово на естественном человеческом языке может видоизменяться.
Анализируя эту проблему, задумаемся: а действительно ли нам нужно вычислять пересечение исходных сегментов? Нельзя ли, вычислив пересечение целевых сегментов (то есть UNL-предложений), сформировать для него перевод обратно на исходный язык автоматически? Положительный ответ на эти вопросы можно дать, если снова воспользоваться технологией машинного перевода. Действительно, для всех концептов имеется их перевод на исходный язык, следовательно, слабое место машинного перевода- выбор лексики- удастся избежать. Все, что будет требоваться от компьютера- это выделить в исходном сегменте те слова и синтаксические связи, которые вошли в состав пересечения UNL-предложений, и сформировать новое словосочетание, нужным образом изменив формы слов (рис. 7).
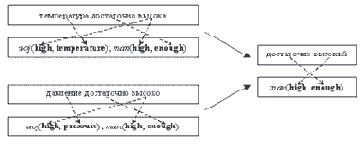
Рис. 7
Коль скоро мы доверили системе машинного перевода синтаксический и морфологический разбор исходного сегмента, когда оценивали изоморфизм пересечения языковых пар без привлечения UNL, доверим ей сделать то же самое для организации поиска сегмента в памяти переводов. В самом деле, почему бы не преобразовать исходный сегмент в UNL-предложение и не осуществить поиск в графе сегментов, хранящих текст на языке UNL? Поступив подобным образом, мы полностью избавимся от необходимости осуществлять операции поиска и добавления над графом сегментов, хранящих текст на естественном языке. Все операции будут производиться над графом UNL-предложений. Теперь вместо нескольких графов (по одному на каждый язык) память переводов будет использовать один единственный граф, каждый узел которого будет представлять собой языковую звезду с UNL-предложением в центре и вариантами перевода на лучах.
Весь процесс работы переводчика с предлагаемой системой описывается схемой, изображенной на рис. 8.
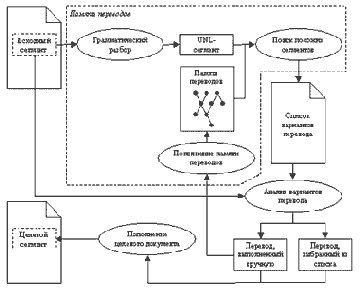
Рис. 8
Важным фактором является то, что работа классической памяти переводов описывается такой же схемой. Это означает, что реализация предлагаемой модели может быть легко встроена в существующие системы.
