Множественное наследование
В языке Си++ имеется возможность в качестве базовых задать несколько классов. В таком случае производный класс наследует методы и атрибуты всех его родителей. Пример иерархии классов в случае множественного наследования приведен на следующем рисунке.

10.2. Иерархия классов при множественном наследовании.
В данном случае класс C наследует двум классам, A и B.
Множественное наследование – мощное средство языка. Приведем некоторые примеры использования множественного наследования.
Предположим, имеющуюся библиотечную систему решено установить в университете и интегрировать с другой системой учета преподавателей и студентов. В библиотечной системе имеются классы, описывающие читателей и работников библиотеки. В системе учета кадров существуют классы, хранящие информацию о преподавателях и студентах. Используя множественное наследование, можно создать классы студентов-читателей, преподавателей-читателей и студентов, подрабатывающих библиотекарями.
В графическом редакторе для некоторых фигур может быть предусмотрен пояснительный текст. При этом все алгоритмы форматирования и печати пояснений работают с классом Annotation. Тогда те фигуры, которые могут содержать пояснение, будут представлены классами, производными от двух базовых классов:
class Annotation { public: String GetText(void); private: String annotation; }; class Shape { public: virtual void Draw(void); }; class AnnotatedSquare : public Shape, public Annotation { public: virtual void Draw(); };
У объекта класса AnnotatedSquare имеется метод GetText, унаследованный от класса Annotation, он определяет виртуальный метод Draw, унаследованный от класса Shape.
При применении множественного наследования возникает ряд проблем. Первая из них – возможный конфликт имен методов или атрибутов нескольких базовых классов.
class A { public: void fun(); int a; }; class B { public: int fun(); int a; }; class C : public A, public B { };
При записи
C* cp = new C; cp-fun();
невозможно определить, к какому из двух методов fun происходит обращение. Ситуация называется неоднозначной, и компилятор выдаст ошибку. Заметим, что ошибка выдается не при определении класса C, в котором заложена возможность возникновения неоднозначной ситуации, а лишь при попытке вызова метода fun.
Неоднозначность можно разрешить, явно указав, к которому из базовых классов происходит обращение:
cp-A::fun();
Вторая проблема заключается в возможности многократного включения базового класса. В упомянутом выше примере интеграции библиотечной системы и системы кадров вполне вероятна ситуация, при которой классы для работников библиотеки и для студентов были выведены из одного и того же базового класса Person:
class Person { public: String name(); }; class Student : public Person { . . . }; class Librarian : public Person { . . . };
Если теперь создать класс для представления студентов, подрабатывающих в библиотеке
class StudentLibrarian : public Student, public Librarian { };
то объект данного класса будет содержать объект базового класса Person дважды (см. 10.3).
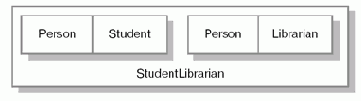
10.3. Структура объекта StudentLibrarian.
Кроме того, что подобная ситуация отражает нерациональное использование памяти, никаких неудобств в данном случае она не вызывает. Возможную неоднозначность можно разрешить, явно указав класс:
StudentLibrarian* sp; // ошибка – неоднозначное обращение, // непонятно, к какому именно экземпляру // типа Person обращаться sp-Person::name(); // правильное обращение sp-Student::Person::name();
Тем не менее, иногда необходимо, чтобы объект базового класса содержался в производном один раз. Для этих целей применяется виртуальное наследование, речь о котором впереди.
Преобразование базового и производного классов
Объект базового класса является частью объекта производного класса. Если в программе используется указатель на производный класс, то его всегда можно без потери информации преобразовать в указатель на базовый класс. Поэтому во многих случаях компилятор может выполнить такое преобразование автоматически.
Circle* pC; . . . Shape* pShape = pC;
Обратное не всегда верно. Преобразование из базового класса в производный не всегда можно выполнить. Поэтому говорят, что преобразование
Item* iPtr; . . . Book* bPtr = (Book*)iPtr;
небезопасно. Такое преобразование можно выполнять только тогда, когда точно известно, что iPtr указывает на объект класса Book.
Виртуальные методы
В обоих классах, выведенных из класса Item, имеется метод Title, выдающий в качестве результата заглавие книги или название журнала. Кроме этого метода, полезно было бы иметь метод, выдающий полное название любой единицы хранения. Реализация этого метода различна, поскольку название книги и журнала состоит из разных частей. Однако вид метода – возвращаемое значение и аргументы – и его общий смысл один и тот же. Название – это общее свойство всех единиц хранения в библиотеке, и логично поместить метод, выдающий название, в базовый класс.
class Item { public: virtual String Name(void) const; . . . }; class Book : public Item { public: virtual String Name(void) const; . . . }; class Magazine : public Item { public: virtual String Name(void) const; . . . };
Реализация метода Name для базового класса тривиальна: поскольку название известно только производному классу, мы будем возвращать пустую строку.
String Item::Name(void) const { return ""; }
Для книги название состоит из фамилии автора, названия книги, издательства и года издания:
String Book::Name(void) const { return author + title + publisher + String(year); }
У журнала полное название состоит из названия журнала, года и номера:
String Magazine::Name(void) const { return title + String(year) + String(number); }
Методы Name определены как виртуальные с помощью описателя virtual, стоящего перед определением метода. Виртуальные методы реализуют идею полиморфизма в языке Си++. Если в программе используется указатель на базовый класс Item и с его помощью вызывается метод Name:
Item* ptr; . . . String name = ptr-Name();
то по виду вызова метода невозможно определить, какая из трех приведенных выше реализаций Name будет выполнена. Все зависит от того, на какой конкретный объект указывает указатель ptr.
Item* ptr; . . . if (type == "Book") ptr = new Book; else if (type == "Magazine") ptr = new Magazine; . . . String name = ptr-Name();
В данном фрагменте программы, если переменная type, обозначающая тип библиотечной единицы, была равна "Book", то будет вызван метод Name класса Book. Если же она была равна "Magazine", то будет вызван метод класса Magazine.
Виртуальные методы позволяют программировать действия, общие для всех производных классов, в терминах базового класса. Динамически, во время выполнения программы, будет вызываться метод нужного класса.
Приведем еще один пример виртуального метода. Предположим, в графическом редакторе при нажатии определенной клавиши нужно перерисовать текущую форму на экране. Форма может быть квадратом, кругом, эллипсом и т.д. Мы введем базовый класс для всех форм Shape. Конкретные фигуры, с которыми работает редактор, будут представлены классами Square (квадрат), Circle (круг), Ellipse (эллипс), производными от класса Shape. Класс Shape определяет виртуальный метод Draw для отображения формы на экране.
class Shape { public: Shape(); virtual void Draw(void); }; // // квадрат // class Square : public Shape { public: Square(); virtual void Draw(void); private: double length; // длина стороны }; // // круг // class Circle : public Shape { public: Circle(); virtual void Draw(void); private: short radius; }; . . .
Конкретные классы реализуют данный метод, и, разумеется, делают это по-разному. Однако в функции перерисовки текущей формы, если у нас имеется указатель на базовый класс, достаточно лишь записать вызов виртуального метода, и динамически будет вызван нужный алгоритм рисования конкретной формы в зависимости от того, к какому из классов (Square, Circle и т.д.) принадлежит объект, на который указывает указатель shape:
Repaint(Shape* shape) { shape-Draw(); }
Виртуальные методы и переопределение методов
Что бы изменилось, если бы метод Name не был описан как виртуальный? В таком случае решение о том, какой именно метод будет выполняться, принимается статически, во время компиляции программы. В примере с методом Name, поскольку мы работаем с указателем на базовый класс, был бы вызван метод Name класса Item. При определении метода как virtual решение о том, какой именно метод будет выполняться, принимается во время выполнения.
Свойство виртуальности проявляется только тогда, когда обращение к методу идет через указатель или ссылку на объект. Указатель или ссылка могут указывать как на объект базового класса, так и на объект производного класса. Если же в программе имеется сам объект, то уже во время компиляции известно, какого он типа и, соответственно, виртуальность не используется.
func(Item item) { item.Name(); } func1(Item item) { item.Name();
}
// вызывается метод Item::Name()
// вызывается метод в соответствии // с типом того объекта, на который // ссылается item
Доступ к объекту по чтению и записи
Кроме контроля доступа к атрибутам класса с помощью разделения класса на внутреннюю, защищенную и внешнюю части, нужно следить за тем, с помощью каких методов можно изменить текущее значение объекта, а с помощью каких – нельзя.
При описании метода класса как const выполнение метода не может изменять значение объекта, который этот метод выполняет.
class A { public: int GetValue (void) const; int AddValue (int x) const; private: int value; } int A::GetValue(void) const { return value; } // объект не изменяется int A::AddValue(int x) const { value += x; // попытка изменить атрибут объекта // приводит к ошибке компиляции
return value; }
Таким образом, использование описателя const позволяет программисту контролировать возможность изменения информации в программе, тем самым предупреждая ошибки.
В описании класса String один из методов – GetLength – представлен как неизменяемый (в конце описания метода стоит слово const). Это означает, что вызов данного метода не изменяет текущее значение объекта. Остальные методы изменяют его значение. Контроль использования тех или иных методов ведется на стадии компиляции. Например, если аргументом какой-либо функции объявлена ссылка на неизменяемый объект, то, соответственно, эта функция может вызывать только методы, объявленные как const:
int Lexer::CharCounter(const String s, char c) { int n = s.GetLength(); // допустимо s.Concat("ab"); // ошибка – Concat изменяет значение s }
Общим правилом является объявление всех методов как неизменяемых, за исключением тех, которые действительно изменяют значение объекта. Иными словами, объявляйте как можно больше методов как const. Такое правило соответствует правилу объявления аргументов как const. Объявление константных аргументов запрещает изменение объектов во время выполнения функции и тем самым предотвращает случайные ошибки.
Интерфейс и состояние объекта
Основной характеристикой класса с точки зрения его использования является интерфейс, т.е. перечень методов, с помощью которых можно обратиться к объекту данного класса. Кроме интерфейса, объект обладает текущим значением или состоянием, которое он хранит в атрибутах класса. В Си++ имеются богатые возможности, позволяющие следить за тем, к каким частям класса можно обращаться извне, т.е. при использовании объектов, и какие части являются "внутренними", необходимыми лишь для реализации интерфейса.
Определение класса можно поделить на три части – внешнюю, внутреннюю и защищенную. Внешняя часть предваряется ключевым словом public , после которого ставится двоеточие. Внешняя часть – это определение интерфейса. Методы и атрибуты, определенные во внешней части класса, доступны как объектам данного класса, так и любым функциям и объектам других классов. Определением внешней части мы контролируем способ обращения к объекту. Предположим, мы хотим определить класс для работы со строками текста. Прежде всего, нам надо соединять строки, заменять заглавные буквы на строчные и знать длину строк. Соответственно, эти операции мы поместим во внешнюю часть класса:
class String { public: // добавить строку в конец текущей строки void Concat(const String str); // заменить заглавные буквы на строчные void ToLower(void); int GetLength(void) const; // сообщить длину строки . . . };
Внутренняя и защищенная части класса доступны только при реализации методов этого класса. Внутренняя часть предваряется ключевым словом private, защищенная – ключевым словом protected.
class String { public: // добавить строку в конец текущей строки void Concat(const String str); // заменить заглавные буквы на строчные void ToLower(void); int GetLength(void) const; // сообщить длину строки private: char* str; int length; };
В большинстве случаев атрибуты во внешнюю часть класса не помещаются, поскольку они представляют состояние объекта, и возможности их использования и изменения должны быть ограничены. Представьте себе, что произойдет, если в классе String будет изменен указатель на строку без изменения длины строки, которая хранится в атрибуте length.
Объявляя атрибуты str и length как private, мы говорим, что непосредственно к ним обращаться можно только при реализации методов класса, как бы изнутри класса (private по-английски – частный, личный). Например:
int String::GetLength(void) const { return length; }
Внутри определения методов класса можно обращаться не только к внутренним атрибутам текущего объекта, но и к внутренним атрибутам любых других известных данному методу объектов того же класса. Реализация метода Concat будет выглядеть следующим образом:
void String::Concat(const String x) { length += x.length; char* tmp = new char[length + 1]; ::strcpy(tmp, str); ::strcat(tmp, x.str); delete [] str; str = tmp; }
Однако если в программе будет предпринята попытка обратиться к внутреннему атрибуту или методу класса вне определения метода, компилятор выдаст ошибку, например:
main() { String s; if (s.length 0) // ошибка . . . }
Разница между защищенными (protected) и внутренними атрибутами была описана в предыдущей лекции, где рассматривалось создание иерархий классов.
При записи классов мы помещаем первой внешнюю часть, затем защищенную часть и последней – внутреннюю часть. Дело в том, что внешняя часть определяет интерфейс, использование объектов данного класса. Соответственно, при чтении программы эта часть нужна прежде всего. Защищенная часть необходима при разработке зависимых от данного класса новых классов. И внутреннюю часть требуется изучать реже всего – при разработке самого класса.
Использование описателя const
Во многих примерах мы уже использовали ключевое слово const для обозначения того, что та или иная величина не изменяется. В данном параграфе приводятся подробные правила употребления описателя const.
Если в начале описания переменной стоит описатель const, то описываемый объект во время выполнения программы не изменяется:
const double pi = 3.1415; const Complex one(1,1);
Если const стоит перед определением указателя или ссылки, то это означает, что не изменяется объект, на который данный указатель или ссылка указывает:
// указатель на неизменяемую строку const char* ptr = string; char x = *ptr; ptr++; *ptr = '0'; // обращение по указателю — допустимо // изменение указателя — допустимо // попытка изменения объекта, на // который указатель указывает – // ошибка
Если нужно объявить указатель, значение которого не изменяется, то такое объявление выглядит следующим образом:
char* const ptr = string; // неизменяемый указатель char x = *ptr; ptr++; *ptr = '0'; // обращение по указателю – допустимо // изменение указателя – ошибка // изменение объекта, на который // указатель указывает – допустимо
Деструкторы
Аналогично тому, что при создании объекта выполняется конструктор, при уничтожении объекта выполняется специальный метод класса, называемый деструктором. Обычно деструктор освобождает ресурсы, использованные данным объектом.
У класса может быть только один деструктор. Его имя – это имя класса, перед которым добавлен знак "тильда" ‘~’. Для объектов класса String деструктор должен освободить память, используемую для хранения строки:
class String { ~String(); }; String::~String() { if (str) delete str; }
Если деструктор в определении класса не объявлен, то при уничтожении объекта никаких действий не производится.
Деструктор всегда вызывается перед тем, как освобождается память, выделенная под объект. Если объект типа String был создан с помощью операции new, то при вызове
delete sptr;
выполняется деструктор ~String(), а затем освобождается память, занимаемая этим объектом. Предположим, в некой функции объявлена автоматическая переменная типа String:
int funct(void) { String str; . . . return 0; }
При выходе из функции funct по оператору return переменная str будет уничтожена: выполнится деструктор и затем освободится память, занимаемая этой переменной.
В особых случаях деструктор можно вызвать явно:
sptr-~String();
Такие вызовы встречаются довольно редко; соответствующие примеры будут рассматриваться позже, при описании переопределения операций new и delete.
Инициализация объектов
Рассмотрим более подробно, как создаются объекты. Предположим, формируется объект типа Book.
Во-первых, под объект выделяется необходимое количество памяти: либо динамически, если объект создается с помощью операции new, либо автоматически – при создании автоматической переменной, либо статически – при создании статической переменной.
Класс Book – производный от класса Item, поэтому вначале вызывается конструктор Item.
У объекта класса Book имеются атрибуты – объекты других классов, в частности, String. После завершения конструктора базового класса будут созданы все атрибуты, т.е. вызваны их конструкторы. По умолчанию используются стандартные конструкторы, как для базового класса, так и для атрибутов.
И только теперь очередь дошла до вызова конструктора класса Book.
В самом конце, после завершения конструктора Book, создаются структуры, необходимые для работы виртуального механизма (отсюда следует, что в конструкторе нельзя использовать виртуальный механизм).
Вызов конструкторов базового класса и конструкторов для атрибутов класса можно задать явно. Особенно это важно, если есть необходимость либо использовать нестандартные конструкторы, либо присвоить начальные значения атрибутам класса. Вызов конструкторов записывается после имени конструктора класса после двоеточия. Друг от друга вызовы отделяются запятой. Такой список называется списком инициализации или просто инициализацией:
Item::Item() : taken(false), invNumber(0) {}
В данном случае атрибутам объекта присваиваются начальные значения. Для класса Book конструктор может выглядеть следующим образом:
Book::Book() : Item(), title("None"), author("None"), publisher("None"), year(-1) {}
Вначале выполняется стандартный конструктор класса Item, а затем создаются атрибуты объекта с некими начальными значениями. Теперь предположим, что у классов Item и Book есть не только стандартные конструкторы, но и конструкторы, которые задают начальные значения атрибутов. Для класса Item конструктор задает инвентарный номер единицы хранения.
class Item { public: Item(long in) { invNumber = in; }; . . . }; class Book { public: Book( long in, const String a, const String t); . . . };
Тогда конструктор класса Book имеет смысл записать так:
Book::Book(long in, const String a, const String t) : Item(in), author(a), title(t) {}
Такого же результата можно добиться и при другой записи:
Book::Book(long in, const String a, const String t) : Item(in) { author = a; title = t; }
Однако предыдущий вариант лучше. Во втором случае вначале для атрибутов author и title объекта типа Book вызываются стандартные конструкторы. Затем программа выполнит операции присваивания новых значений. В первом же случае для каждого атрибута будет выполнен лишь один копирующий конструктор. Посмотрев на реализацию класса String, вы можете убедиться, насколько эффективнее первый вариант конструктора класса Book.
Встречается еще один случай, когда без инициализации обойтись невозможно. В качестве атрибута класса можно определить ссылку. Однако при создании ссылки ее необходимо инициализировать, поэтому в конструкторе подобного класса нужно применять инициализацию.
class A { public: A(const String x); private: String str_ref; }; A::A(const String x) : str_ref(x) {}
Создавая объект класса A, мы задаем строку, на которую он будет ссылаться. Ссылка инициализируется во время конструирования объекта. Поскольку ссылку нельзя переопределить, все время жизни объект класса A будет ссылаться на одну и ту же строку. Выбор ссылки в качестве атрибута класса обычно как раз и определяется тем, что ссылка инициализируется при создании объекта и никогда не изменяется. Тем самым дается гарантия использования ссылки на одну и ту же переменную. Значение переменной может изменяться, но сама ссылка – никогда.
Рассмотрим еще один пример использования ссылки в качестве атрибута класса. Предположим, что в нашей библиотечной системе книги, журналы, альбомы и т.д. могут храниться в разных хранилищах. Хранилище описывается объектом класса Repository. У каждого элемента хранения есть атрибут, указывающий на его хранилище. Здесь может быть два варианта. Первый вариант – элемент хранения хранится всегда в одном и том же месте, переместить книгу из одного хранилища в другое нельзя. В данном случае использование ссылки полностью оправдано:
class Repository { . . . }; class Item { public: Item(Repository rep) : myRepository(rep) {}; . . . private: Repository myRepository; };
При создании объекта необходимо указать, где он хранится. Изменить хранилище нельзя, пока данный объект не уничтожен. Атрибут myRepository всегда ссылается на один и тот же объект.
Второй вариант заключается в том, что книги можно перемещать из одного хранилища в другое. Тогда в качестве атрибута класса Item лучше использовать указатель на Repository:
class Item { public: Item() : myRepository(0) {}; Item(Repository* rep) : myRepository(rep) {}; void MoveItem(Repository* newRep); . . . private: Repository* myRepository; };
Создавая объект Item, можно указать, где он хранится, а можно и не указывать. Впоследствии можно изменить хранилище, например с помощью метода MoveItem.
При уничтожении объекта вызов деструкторов происходит в обратном порядке. Вначале вызывается деструктор самого класса, затем деструкторы атрибутов этого класса и, наконец, деструктор базового класса.
В создании и уничтожении объектов имеется одно существенное отличие. Создавая объект, мы всегда точно знаем, какому классу он принадлежит. При уничтожении это не всегда известно.
Item* itptr; if (type == "book") itptr = new Book(); else itptr = new Magazin(); . . . delete itptr;
Во время компиляции неизвестно, каким будет значение переменной type и, соответственно, объект какого класса удаляется операцией delete. Поэтому компилятор может вставить вызов только деструктора базового класса.
Для того чтобы все необходимые деструкторы были вызваны, нужно воспользоваться виртуальным механизмом – объявить деструктор как в базовом классе, так и в производном, как virtual.
class Item { virtual ~Item(); }; class Book { public: virtual ~Book(); };
Возникает вопрос – почему бы всегда не объявлять деструкторы виртуальными? Единственная плата за это – небольшое увеличение памяти для реализации виртуального механизма. Таким образом, не объявлять деструктор виртуальным имеет смысл только в том случае, если во всей иерархии классов нет виртуальных функций, и удаление объекта никогда не происходит через указатель на базовый класс.
Копирующий конструктор
Остановимся чуть подробнее на одном из видов конструктора с аргументом, в котором в качестве аргумента выступает объект того же самого класса. Такой конструктор часто называют копирующим, поскольку предполагается, что при его выполнении создается объект-копия другого объекта. Для класса String он может выглядеть следующим образом:
class String { public: String(const String s); }; String::String(const String s) { length = s.length; str = new char[length + 1]; strcpy(str, s.str); }
Очевидно, что новый объект будет копией своего аргумента. При этом новый объект независим от первоначального в том смысле, что изменение значения одного не изменяет значения другого.
// первый объект с начальным значением // "Astring" String a("Astring"); // новый объект – копия первого, // т.е. со значением "Astring" String b(a); // изменение значения b на "AstringAstring", // значение объекта a не изменяется b.Concat(a);
Столь логичное поведение объектов класса String на самом деле обусловлено наличием копирующего конструктора. Если бы его не было, компилятор создал бы его по умолчанию, и такой конструктор просто копировал бы все атрибуты класса, т.е. был бы эквивалентен:
String::String(const String s) { length = s.length; str = s.str; }
При вызове метода Concat для объекта b произошло бы следующее: объект b перераспределил бы память под строку str, выделив новый участок памяти и удалив предыдущий (см. определение метода выше). Однако указатель str объекта a по-прежнему указывает на первоначальный участок памяти, только что освобожденный объектом b. Соответственно, значение объекта a испорчено.
Для класса Complex, который мы рассматривали ранее, кроме стандартного конструктора можно задать конструктор, строящий комплексное число из целых чисел:
class Complex { public: Complex(); Complex(int rl, int im = 0); Complex(const Complex c); // прибавить комплексное число Complex operator+(const Complex x) const; private: int real; // вещественная часть int imaginary; // мнимая часть
}; // // Стандартный конструктор создает число (0,0) // Complex::Complex() : real(0), imaginary(0) {} // // Создать комплексное число из действительной // и мнимой частей. У второго аргумента есть // значение по умолчанию — мнимая часть равна // нулю Complex::Complex(int rl, int im) : real(rl), imaginary(im) {} // // Скопировать значение комплексного числа // Complex::Complex(const Complex c) : real(c.real), imaginary(c.imaginary) {}
Теперь при создании комплексных чисел происходит их инициализация:
Complex x1; // начальное значение – ноль Complex x2(3); // мнимая часть по умолчанию равна 0 // создается действительное число 3 Complex x3(0, 1); // мнимая единица Complex y(x3); // мнимая единица
Конструкторы, особенно копирующие, довольно часто выполняются неявно. Предположим, мы бы описали метод Concat несколько иначе:
Concat(String s);
вместо
Concat(const String s);
т.е. использовали бы передачу аргумента по значению вместо передачи по ссылке. Конечный результат не изменился бы, однако при вызове метода
b.Concat(a)
компилятор создал бы временную переменную типа String – копию объекта a, и передал бы ее в качестве аргумента. При выходе из метода String эта переменная была бы уничтожена. Представляете, насколько снизилось бы быстродействие метода!
Второй пример вызова конструктора – неявное преобразование типа. Допустима запись вида:
b.Concat("LITERAL");
хотя сам метод определен только для аргумента – объекта типа String. Поскольку в классе String есть конструктор с аргументом – указателем на байт (а литерал – как раз константа такого типа), компилятор произведет автоматическое преобразование. Будет создана автоматическая переменная типа String с начальным значением "LITERAL", ссылка на нее будет передана в качестве аргумента метода String, а по завершении Concat временная переменная будет уничтожена.
Чтобы избежать подобного неэффективного преобразования, можно определить отдельный метод для работы с указателями:
class String { public: void Concat(const String s); void Concat(const char* s); }; void String::Concat(const char* s) { length += strlen(s); char* tmp = new char[length + 1]; if (tmp == 0) { // обработка ошибки } strcpy(tmp, str); strcat(tmp, s); delete [] str; str = tmp; }
Операции new и delete
Выделение памяти под объекты некоего класса производится либо при создании переменных типа этого класса, либо с помощью операции new. Эти операции, как и другие операции класса, можно переопределить.
Прежде всего, рассмотрим модификацию операции new, которая уже определена в самом языке. (Точнее, она определена в стандартной библиотеке языка Си++.) Эта операция не выделяет память, а лишь создает объект на заранее выделенном участке памяти. Форма операции следующая:
new (адрес) имя_класса (аргументы_конструктора)
Перед именем класса в круглых скобках указывается адрес, по которому должен располагаться создаваемый объект. Фактически, такая операция new не выделяет памяти, а лишь создает объект по указанному адресу, выполняя его конструктор. Соответственно, можно не выполнять операцию delete для этого объекта, а лишь вызвать его деструктор перед тем, как поместить новый объект на то же место памяти.
char memory_chunk[4096]; Book* bp = new (memory_chunk) Book; . . . bp-~Book(); Magazin* mp = new (memory_chunk) Magazin; . . . mp-~Magazin();
В этом примере никакой потери памяти не происходит. Память выделена один раз, объявлением массива memory_chunk. Операции new создают объекты в начале этого массива (разумеется, мы предполагаем, что 4096 байтов для объектов достаточно). Когда объект становится ненужным, явно вызывается его деструктор и на том же месте создается новый объект.
Любой класс может использовать два вида операций new и delete – глобальную и определенную для класса. Если класс и ни один из его базовых классов, как прямых, так и косвенных, не определяет операцию new, то используется глобальная операция new. Глобальная операция new всегда используется для выделения памяти под встроенные типы и под массивы (независимо от того, объекты какого класса составляют массив).
Если класс определит операцию new, то для всех экземпляров этого класса и любых классов, производных от него, глобальная операция будет переопределена, и будет использоваться new данного класса. Если нужно использовать именно глобальную операцию, можно перед new поставить два двоеточия ::new.
Вид стандартной операции new следующий:
class A { void* operator new(size_t size); };
Аргумент size задает размер необходимой памяти в байтах. size_t – это тип целого, подходящий для установления размера объектов в данной реализации языка, определенный через typedef. Чаще всего это тип long. Аргумент операции new явно при ее вызове не задается. Компилятор сам его подставляет, исходя из размера создаваемого объекта.
Реализация операции new, которая совпадает со стандартной, выглядит просто:
void* A::operator new(size_t size) { return ::new char[size]; }
В классе может быть определено несколько операций new с различными дополнительными аргументами. При вызове new эти аргументы указываются сразу после ключевого слова new в скобках до имени типа. Компилятор добавляет от себя еще один аргумент – размер памяти, и затем вызывает соответствующую операцию. Описанная выше модификация new, помещающая объект по определенному адресу, имеет вид:
void* operator new(void* addr, size_t size);
Предположим, мы хотим определить такую операцию, которая будет инициализировать каждый байт выделенной памяти каким-либо числом.
class A { void* operator new(char init, size_t size); }; void* A::operator new(char init, size_t size) { char* result = ::new char[size]; if (result) { for (size_t i = 0; i size; i++) result[i] = init; } return result; }
Вызов такой операции имеет вид:
A* aptr = new (32) A;
Память под объект класса A будет инициализирована числом 32 (что, кстати, является кодом пробела).
Отметим, что если класс определяет хотя бы одну форму операции new, глобальная операция будет переопределена. Например, если бы в классе A была определена только операция new с инициализацией, то вызов
A* ptr = new A;
привел бы к ошибке компиляции, поскольку подобная форма new в классе не определена. Поэтому, если вы определяете new, определяйте все ее формы, включая стандартную (быть может, просто вызывая глобальную операцию).
В отличие от операции new, для которой можно определить разные модификации в зависимости от числа и типов аргументов, операция delete существует только в единственном варианте:
void operator delete (void* addr);
В качестве аргумента ей передается адрес, который в свое время возвратила операция new для данного объекта. Соответственно, для класса можно определить только одну операцию delete. Напомним, что операция delete ответственна только за освобождение занимаемой памяти. Деструктор объекта вызывается отдельно. Операция delete, которая будет вызывать стандартную форму, выглядит следующим образом:
void A::operator delete(void* addr) { ::delete [] (char*)addr; }
Явные преобразования типов
Если перед выражением указать имя типа в круглых скобках, то значение выражения будет преобразовано к указанному типу:
double x = (double)1; void* addr; Complex* cptr = (Complex*) addr;
Такие преобразования типов использовались в языке Си. Их основным недостатком является полное отсутствие контроля. Явные преобразования типов традиционно использовались в программах на языке Си и, к сожалению, продолжают использоваться в Си++, что приводит и к ошибкам, и к путанице в программах. В большинстве своем ошибок в Си++ можно избежать. Тем не менее, иногда явные преобразования типов необходимы.
Для того чтобы преобразовывать типы, хотя бы с минимальным контролем, можно записать
static_cast тип (выражение)
Операция static_cast позволяет преобразовывать типы, основываясь лишь на сведениях о типах выражений, известных во время компиляции. Иными словами, static_cast не проверяет типы выражений во время выполнения. С одной стороны, это возлагает на программиста большую ответственность, а с другой — ускоряет выполнение программ. С помощью static_cast можно выполнять как стандартные преобразования, так и нестандартные. Операция static_cast позволяет преобразовывать типы, связанные отношением наследования, указатель к указателю, один числовой тип к другому, перечислимое значение к целому. В частности, с помощью операции static_cast можно преобразовывать не только указатель на производный класс к базовому классу, но и указатель на базовый класс к производному, что в общем случае небезопасно.
Однако попытка преобразовать целое число к указателю приведет к ошибке компиляции. Если все же необходимо преобразовать совершенно не связанные между собой типы, можно вместо static_cast записать reinterpret_cast:
void* addr; int* intPtr = static_cast int* (addr); Complex* cPtr = reinterpret_cast Complex* (2000);
Если необходимо ограниченное преобразование типа, которое только преобразует неизменяемый тип к изменяемому (убирает описатель const), можно воспользоваться операцией const_cast:
const char* addr1; char* addr2 = const_cast char* addr1;
Использование static_cast, const_cast и reinterpret_cast вместо явного преобразования в форме (тип) имеет существенные преимущества. Во-первых, можно всегда применить "минимальное" преобразование, т. е. преобразование, которое меньше всего изменяет тип. Во-вторых, все преобразования можно легко обнаружить в программе. В-третьих, легче распознать намерения программиста, что важно при модификации программы. Сразу можно будет отличить неконтролируемое преобразование от преобразования неизменяемого указателя к изменяемому.
Переопределение операций
Язык Си++ позволяет определять в классах особого вида методы – операции. Они называются операциями потому, что их запись имеет тот же вид, что и запись операции сложения, умножения и т.п. со встроенными типами языка Си++.
Определим две операции в классе String – сравнение на меньше и сложение:
class String { public: . . . String operator+(const String s) const; bool operator(const String s) const; };
Признаком того, что переопределяется операция, служит ключевое слово operator, после которого стоит знак операции. В остальном операция мало чем отличается от обычного метода класса. Теперь в программе можно записать:
String s1, s2; . . . s1 + s2
Объект s1 выполнит метод operator с объектом s2 в качестве аргумента.
Результатом операции сложения является объект типа String. Никакой из аргументов операции не изменяется. Описатель const при описании аргумента говорит о том, что s2 не может измениться при выполнении сложения, а описатель const в конце определения операции говорит то же самое об объекте, выполняющем сложение.
Реализация может выглядеть следующим образом:
String String::operator+(const String s) const { String result; result.length = length + s.length; result.str = new char[result.length + 1]; strcpy(result.str, str); strcat(result.str, s.str); return result; }
При сравнении на меньше мы будем сравнивать строки в лексикографической последовательности. Проще говоря, меньше та строка, которая должна стоять раньше по алфавиту:
bool String::operator(const String s) const { char* cp1 = str; char* cp2 = s.str; while (true) { if (*cp1 *cp2) return true; else if (*cp1 *cp2) return false; else { cp1++; cp2++; if (*cp2 == 0) // конец строки return false; else if (*cp1 == 0) // конец строки return true; } } }
Преобразования типов
Определяя класс, программист задает методы и операции, которые применимы к объектам этого класса. Например, при определении класса комплексных чисел была определена операция сложения двух комплексных чисел. При определении класса строк мы определили операцию конкатенации двух строк. Что же происходит, если в выражении мы попытаемся использовать ту же операцию сложения с типами, для которых она явно не задана? Компилятор пытается преобразовать величины, участвующие в выражении, к типам, для которых операция задана. Это преобразование, называемое преобразованием типов, выполняется в два этапа.
Первый этап – попытка воспользоваться стандартными преобразованиями типов, определенными в языке Си++ для встроенных типов. Если это не помогает, тогда компилятор пытается применить преобразования, определенные пользователем. "Помочь" компилятору правильно преобразовать типы величин можно, явно задав преобразования типов.
Преобразования указателей и ссылок
При работе с указателями и ссылками компилятор автоматически выполняет только два вида преобразований.
Если имеется указатель или ссылка на производный тип, а требуется, соответственно, указатель или ссылка на базовый тип.
Если имеется указатель или ссылка на изменяемый объект, а требуется указатель или ссылка на неизменяемый объект того же типа.
size_t strlen(const char* s); // прототип функции class A { }; class B : public A { }; char* cp; strlen(cp); // автоматическое преобразование из // char* в const char*
B* bObj = new B; // преобразование из указателя на A* aObj = bObj; // производный класс к указателю на // базовый класс
Если требуются какие-то другие преобразования, их необходимо указывать явно, но в этом случае вся ответственность за правильность преобразования лежит на программисте.
Стандартные преобразования типов
К стандартным преобразованиям относятся преобразования целых типов и преобразования указателей. Они выполняются компилятором автоматически. Часть правил преобразования мы уже рассмотрели ранее. Преобразования целых величин, при которых не теряется точность, сводятся к следующим:
Величины типа char, unsigned char, short или unsigned short преобразуются к типу int, если точность типа int достаточна, в противном случае они преобразуются к типу unsigned int. Величины типа wchar_t и константы перечисленных типов преобразуются к первому из типов int, unsigned int, long и unsigned long, точность которого достаточна для представления данной величины. Битовые поля преобразуются к типу int, если точность типа int достаточна, или к unsigned int, если точность unsigned int достаточна. В противном случае преобразование не производится. Логические значения преобразуются к типу int, false становится 0 и true становится 1.
Эти четыре типа преобразований мы будем называть безопасными преобразованиями.
Язык Си (от которого Си++ унаследовал большинство стандартных преобразований) часто критиковали за излишне сложные правила преобразования типов и за их автоматическое применение без ведома пользователя. Основная рекомендация — избегать неявных преобразований типов, в особенности тех, при которых возможна потеря точности или знака.
Правила стандартных преобразований при выполнении арифметических операций следующие:
вначале, если в выражении один из операндов имеет тип long double, то другой преобразуется также к long double; в противном случае, если один из операндов имеет тип double, то другой преобразуется также к double; в противном случае, если один из операндов имеет тип float, то другой преобразуется также к float; в противном случае производится безопасное преобразование.
затем, если в выражении один из операндов имеет тип unsigned long, то другой также преобразуется к unsigned long; в противном случае, если один из операндов имеет тип long, а другой – unsigned int, и тип long может представить все значения unsigned int, то unsigned int преобразуется к long, иначе оба операнда преобразуются к unsigned long; в противном случае, если один из операндов имеет тип long, то другой преобразуется также к long; в противном случае, если один из операндов имеет тип unsigned, то другой преобразуется также к unsigned; в противном случае оба операнда будут типа int.
(1L + 2.3) результат типа double (8u + 4) результат типа unsigned long
Все приведенные преобразования типов производятся компилятором автоматически, и обычно при компиляции даже не выдается никакого предупреждения, поскольку не теряются значащие цифры или точность результата.
Как мы уже отмечали ранее, при выполнении операции присваивания со стандартными типами может происходить потеря точности. Большинство компиляторов при попытке такого присваивания выдают предупреждение или даже ошибку. Например, при попытке присваивания
long x; char c; c = x;
если значение x равно 20, то и c будет равно 20. Но если x равно 500, значение c будет равно -12 (при условии выполнения на персональном компьютере), поскольку старшие биты, не помещающиеся в char, будут обрезаны. Именно поэтому большинство компиляторов выдаст ошибку и не будет транслировать подобные конструкции.
Использование включаемых файлов
В языке Си++ реализовано удобное решение. Можно поместить объявления классов и функций в отдельный файл и включать этот файл в начало других файлов с помощью оператора #include.
#include "Book.h" . . . Book b;
Фактически оператор #include подставляет содержимое файла Book.h в текущий файл перед тем, как начать его компиляцию. Эта подстановка осуществляется во время первого прохода компилятора по программе – препроцессора. Файл Book.h называется файлом заголовков.
В такой же файл заголовков можно поместить прототипы функций и включать его в другие файлы, там, где функции используются.
Таким образом, текст программы на языке Си++ помещается в файлы двух типов – файлы заголовков и файлы программ. В большинстве случаев имеет смысл каждый класс помещать в отдельный файл, вернее, два файла – файл заголовков для объявления класса и файл программ для определения класса. Имя файла обычно состоит из имени класса. Для файла заголовков к нему добавляется окончание ".h" (иногда, особенно в системе Unix, ".hh" или ".H"). Имя файла программы – опять-таки имя класса с окончанием ".cpp" (иногда ".cc" или ".C").
Объединять несколько классов в один файл стоит лишь в том случае, если они очень тесно связаны и один без другого не используются.
Включение файлов может быть вложенным, т.е. файл заголовков может сам использовать оператор #include. Файл Book.h выглядит следующим образом:
#ifndef __BOOK_H__ #define __BOOK_H__
// включить файл с объявлением используемого // здесь базового класса #include "Item .h" #include "String.h" // объявление класса String
// объявление класса Book class Book : public Item { public: . . . private: String title; . . . }; #endif
Обратите внимание на первые две и последнюю строки этого файла. Оператор #ifndef начинает блок так называемой условной компиляции, который заканчивается оператором #endif. Блок условной компиляции – это кусок текста, который будет компилироваться, только если выполнено определенное условие. В данном случае условие заключается в том, что символ __BOOK_H__ не определен. Если этот символ определен, текст между #ifndef и #endif не будет включен в программу. Первым оператором в блоке условной компиляции стоит оператор #define, который определяет символ __BOOK_H__ как пустую строку.
Давайте посмотрим, что произойдет, если в какой-либо .cpp-файл будет дважды включен файл Book.h:
#include "Book.h" . . . #include "Book.h"
Перед началом компиляции текст файла Book.h будет подставлен вместо оператора #include:
#ifndef __BOOK_H__ #define __BOOK_H__ . . . class Book { . . . }; #endif . . . #ifndef __BOOK_H__ #define __BOOK_H__ . . . class Book { . . . }; #endif
В самом начале символ __BOOK_H__ не определен, и блок условной компиляции обрабатывается. В нем определяется символ __BOOK_H__ . Теперь условие для второго блока условной компиляции уже не выполняется, и он будет пропущен. Таким образом, объявление класса Book будет вставлено в файл только один раз. Разумеется, написание два раза подряд оператора #include с одинаковым аргументом легко поправить. Однако структура заголовков может быть очень сложной. Чтобы избежать необходимости отслеживать все вложенные заголовки и искать, почему какой-либо файл оказался вставленным дважды, можно применить изложенный выше прием и существенно упростить себе жизнь.
Еще одно замечание по составлению заголовков. Включайте в заголовок как можно меньше других заголовков. Например, в заголовок Book.h необходимо включить заголовки Item.h и String.h, поскольку класс Book использует их. Однако если используется лишь имя класса без упоминания его содержимого, можно обойтись и объявлением этого имени:
#include "Item.h" #include "String.h"
class Annotation; // Annotation – имя некого класса
class Book : public Item { public: Annotation* CreateAnnotation(); private: String title; };
Объявление класса Item требуется знать целиком, для того, чтобы обработать объявление класса Book, т.е. компилятору надо знать все методы и атрибуты Item, чтобы включить их в класс Book. Объявление класса String также необходимо знать целиком, по крайней мере, для того, чтобы правильно вычислить размер экземпляра класса Book. Что же касается класса Annotation, то ни размер его объектов, ни его методы не важны для определения содержимого объекта класса Book. Единственное, что надо знать, это то, что Annotation есть имя некоего класса, который будет определен в другом месте.
Общее правило таково, что если объявление класса использует указатель или ссылку на другой класс и не задействует никаких методов или атрибутов этого класса, достаточно объявления имени класса. Разумеется, полное объявление класса Annotation понадобится в определении метода CreateAnnotation.
Компилятор поставляется с набором файлов заголовков, которые описывают все стандартные функции и классы. При включении стандартных файлов обычно используют немного другой синтаксис:
Компоновка нескольких файлов в одну программу
Программа – это, прежде всего, текст на языке Си++. С помощью компилятора текст преобразуется в исполняемый файл – форму, позволяющую компьютеру выполнять программу.
Если мы рассмотрим этот процесс чуть более подробно, то выяснится, что обработка исходных файлов происходит в три этапа. Сначала файл обрабатывается препроцессором, который выполняет операторы #include, #define и еще несколько других. После этого программа все еще представлена в виде текстового файла, хотя и измененного по сравнению с первоначальным. Затем, на втором этапе, компилятор создает так называемый объектный файл. Программа уже переведена в машинные инструкции, однако еще не полностью готова к выполнению. В объектном файле имеются ссылки на различные системные функции и на стандартные функции языка Си++. Например, выполнение операции new заключается в вызове определенной системной функции. Даже если в программе явно не упомянута ни одна функция, необходим, по крайней мере, один вызов системной функции – завершение программы и освобождение всех принадлежащих ей ресурсов.
На третьем этапе компиляции к объектному файлу подсоединяются все функции на которые он ссылается. Функции тоже должны быть скомпилированы, т.е. переведены на машинный язык в форму объектных файлов. Этот процесс называется компоновкой, и как раз его результат и есть исполняемый файл.
Системные функции и стандартные функции языка Си++ заранее откомпилированы и хранятся в виде библиотек. Библиотека – это некий архив объектных модулей, с которым удобно компоновать программу.
Основная цель многоэтапной компиляции программ – возможность компоновать программу из многих файлов. Каждый файл представляет собой законченный фрагмент программы, который может ссылаться на функции, переменные или классы, определенные в других файлах. Компоновка объединяет фрагменты в одну "самодостаточную" программу, которая содержит все необходимое для выполнения.
Определение макросов
Форма директивы #define
#define имя определение
определяет макроимя. Везде, где в исходном файле встречается это имя, оно будет заменено его определением. Например, текст:
#define NAME "database" Connect(NAME);
после препроцессора будет заменен на
Connect("database");
По умолчанию имя определяется как пустая строка, т.е. после директивы
#define XYZ
макроимя XYZ считается определенным со значением – пустой строкой.
Другая форма #define
#define имя ( список_имен ) определение
определяет макрос – текстовую подстановку с аргументами
#define max(X, Y) ((X Y) ? X : Y)
Текст max(5, a) будет заменен на
((5 a) ? 5 : a)
В большинстве случаев использование макросов (как с аргументами, так и без) в языке Си++ является признаком непродуманного дизайна. В языке Си макросы были действительно важны, и без них было сложно обойтись. В Си++ при наличии констант и шаблонов макросы не нужны. Макросы осуществляют текстовую подстановку, поэтому они в принципе не могут осуществлять никакого контроля использования типов. В отличие от них в шаблонах контроль типов полностью сохранен. Кроме того, возможности текстовой подстановки существенно меньше, чем возможности генерации шаблонов.
Директива #undef отменяет определение имени, после нее имя перестает быть определенным.
У препроцессора есть несколько макроимен, которые он определяет сам, их называют предопределенными именами. У разных компиляторов набор этих имен различен, но два определены всегда: __FILE__ и __LINE__. Значением макроимени __FILE__ является имя текущего исходного файла, заключенное в кавычки. Значением __LINE__ – номер текущей строки в файле. Эти макроимена часто используют для печати отладочной информации.
Препроцессор
В языке Си++ имеется несколько операторов, которые начинаются со знака #: #include, #define, #undef, #ifdef, #else, #if, #pragma. Все они обрабатываются так называемым препроцессором.
Иногда препроцессор называют макропроцессором, поскольку в нем определяются макросы. Директивы препроцессора начинаются со знака #, который должен быть первым символом в строке после пробелов.
Проблема использования общих функций и имен
В языке Си++ существует строгое правило, в соответствии с которым прежде чем использовать в программе имя или идентификатор, его необходимо определить. Рассмотрим для начала функции. Для того чтобы имя функции стало известно программе, его нужно либо объявить, либо определить.
Объявление функции состоит лишь из ее прототипа, т.е. имени, типа результата и списка аргументов. Объявление функции задает ее формат, но не определяет, как она выполняется. Примеры объявлений функций:
double sqrt(double x);// функция sqrt long fact(long x); // функция fact
// функция PrintBookAnnotation void PrintBookAnnotation(const Book book);
Определение функции – это определение того, как функция выполняется. Оно включает в себя тело функции, программу ее выполнения.
// функция вычисления факториала // целого положительного числа long fact(long x) { if (x == 1) return 1; else return x * fact(x - 1); }
Определение функции играет роль объявления ее имени, т.е. если в начале файла определена функция fact, в последующем тексте функций и классов ею можно пользоваться. Однако если в программе функция fact используется в нескольких файлах, такое построение программы уже не подходит. В программе должно быть только одно Определение функции.
Удобно было бы поместить Определение функции в отдельный файл, а в других файлах в начале помещать лишь объявление, прототип функции.
// начало файла main.cpp long fact(long); // прототип функции int main() { . . . int x10 = fact(10); // вызов функции . . . } // конец файла main.cpp // начало файла fact.cpp // определение функции // вычисления факториала целого // положительного числа // long fact(long x) { if (x == 1) return 1; else return x * fact(x - 1); } // конец файла fact. cpp
Компоновщик объединит оба файла в одну программу.
Аналогичная ситуация существует и для классов. Любой класс в языке Си++ состоит из двух частей: объявления и определения. В объявлении класса говорится, каков интерфейс класса, какие методы и атрибуты составляют объекты этого класса. Объявление класса состоит из ключевого слова class, за которым следует имя класса, список наследования и затем в фигурных скобках - методы и атрибуты класса. Заканчивается объявление класса точкой с запятой.
Условная компиляция
Исходный файл можно компилировать не целиком, а частями, используя директивы условной компиляции:
#if LEVEL 3 текст1 #elif LEVEL 1 текст2 #else текст3 #endif
Предполагается, что LEVEL – это макроимя, поэтому выражение в директивах #if и #elif можно вычислить во время обработки исходного текста препроцессором.
Итак, если LEVEL больше 3, то компилироваться будет текст1, если LEVEL больше 1, то компилироваться будет текст2, в противном случае компилируется текст3. Блок условной компиляции должен завершаться директивой #endif.
В каком-то смысле директива #if похожа на условный оператор if. Однако, в отличие от него, условие – это константа, которая вычисляется на стадии препроцессора, и куски текста, не удовлетворяющие условию, просто игнорируются.
Директив #elif может быть несколько (либо вообще ни одной), директива #else также может быть опущена.
Директива #ifdef – модификация условия компиляции. Условие считается выполненным, если указанное после нее макроимя определено. Соответственно, для директивы #ifndef условие выполнено, если имя не определено.
Файлы и переменные
Автоматические переменные определены внутри какой-либо функции или метода класса. Назначение автоматических переменных – хранение каких-либо данных во время выполнения функции или метода. По завершении выполнения этой функции автоматические переменные уничтожаются и данные теряются. С этой точки зрения автоматические переменные представляют собой временные переменные.
Иногда временное хранилище данных требуется на более короткое время, чем выполнение всей функции. Во- первых, поскольку в Си++ необязательно, чтобы все используемые переменные были определены в самом начале функции или метода, переменную можно определить непосредственно перед тем, как она будет использоваться. Во-вторых, переменную можно определить внутри блока – группы операторов, заключенных в фигурные скобки. При выходе из блока такая переменная уничтожается еще до окончания выполнения функции. Третьей возможностью временного использования переменной является определение переменной в заголовке цикла for только для итераций этого цикла:
funct(int N, Book[] bookArray) { int x; // автоматическая переменная x for (int i = 0; i N; i++) { // переменная i определена только на время // выполнения цикла for String s; // новая автоматическая переменная создается // при каждой итерации цикла заново s.Append(bookArray[i].Title()); s.Append(bookArray[i].Author()); cout s; } cout s; } // ошибка, переменная s не существует
Если переменную, определенную внутри функции или блока, описать как статическую, она не будет уничтожаться при выходе из этого блока и будет хранить свое значение между вызовами функции. Однако при выходе из соответствующего блока эта переменная станет недоступна, иными словами, невидима для программы. В следующем примере переменная allAuthors накапливает список авторов книг, переданных в качестве аргументов функции funct за все ее вызовы:
funct(int n, Book[] bookArray) { for (int i = 0; i n; i++) { static String allAuthors; allAuthors.Append(bookArray[i].Author()); cout allAuthors; // авторы всех ранее обработанных книг, в // том числе в предыдущих вызовах функции } cout allAuthors; // ошибка, переменная недоступна }
Глобальные переменные
Язык Си++ предоставляет возможность определения глобальной переменной. Если переменная определена вне функции, она создается в самом начале выполнения программы (еще до начала выполнения main). Эта переменная доступна во всех функциях того файла, где она определена. Аналогично прототипу функции, имя глобальной переменной можно объявить в других файлах и тем самым предоставить возможность обращаться к ней и в других файлах:
// файл main.cpp #include "RandomGenerator.h" // определение глобальной переменной RandomGenerator rgen; main() { rgen.Init(1000); } void fun1(void) { unsigned long x = rgen.GetNumber(); . . . } // файл class.cpp
#include "RandomGenerator.h" // объявление глобальной переменной, // внешней по отношению к данному файлу extern RandomGenerator rgen; Class1::Class1() { . . . } void fun2() { unsigned long x = rgen.GetNumber(); . . . }
Объявление внешней переменной можно поместить в файл-заголовок. Тогда не нужно будет повторять объявление переменной с описателем extern в каждом файле, который ее использует.
Модификацией определения глобальной переменной является добавление описателя static. Для глобальной переменной описатель static означает то, что эта переменная доступна только в одном файле – в том, в котором она определена. (Правда, в данном примере такая модификация недопустима – нам-то как раз нужно, чтобы к глобальной переменной rgen можно было обращаться из разных файлов.)
Область видимости имен
Между именами переменных, функций, типов и т.п. при использовании одного и того же имени в разных частях программы могут возникать конфликты. Для того чтобы эти конфликты можно было разрешать, в языке существует такое понятие как область видимости имени.
Минимальной областью видимости имен является блок. Имена, определяемые в блоке, должны быть различны. При попытке объявить две переменные с одним и тем же именем произойдет ошибка. Имена, определенные в блоке, видимы (доступны) в этом блоке после описания и во всех вложенных блоках. Аргументы функции, описанные в ее заголовке, рассматриваются как определенные в теле этой функции.
Имена, объявленные в классе, видимы внутри этого класса, т.е. во всех его методах. Для того чтобы обратиться к атрибуту класса, нужно использовать операции ".", "-" или "::".
Для имен, объявленных вне блоков, областью видимости является весь текст файла, следующий за объявлением.
Объявление может перекрывать такое же имя, объявленное во внешней области.
int x = 7; class A { public: void foo(int y); int x; }; int main() { A a; a.foo(x); // используется глобальная переменная x // и передается значение 7 cout x; return 1; } void A::foo(int y) { x = y + 1; { double x = 3.14;
cout x; } cout x; } // x – атрибут объекта типа A
// новая переменная x перекрывает // атрибут класса x
В результате выполнения приведенной программы будет напечатано 3.14, 8 и 7.
Несмотря на то, что имя во внутренней области видимости перекрывает имя, объявленное во внешней области, перекрываемая переменная продолжает существовать. В некоторых случаях к ней можно обратиться, явно указав область видимости с помощью квалификатора "::". Обозначение ::имя говорит о том, что имя относится к глобальной области видимости. (Попробуйте поставить :: перед переменной x в приведенном примере.) Два двоеточия часто употребляют перед именами стандартных функций библиотеки языка Си++, чтобы, во-первых, подчеркнуть, что это глобальные имена, и, во-вторых, избежать возможных конфликтов с именами методов класса, в котором они употребляются.
Если перед квалификатором поставить имя класса, то поиск имени будет производиться в указанном классе. Например, обозначение A::x показало бы, что речь идет об атрибуте класса A. Аналогично можно обращаться к атрибутам структур и объединений. Поскольку определения классов и структур могут быть вложенными, у имени может быть несколько квалификаторов:
class Example { public: enum Color { RED, WHITE, BLUE }; struct Structure { static int Flag; int x; }; int y; void Method(); };
Следующие обращения допустимы извне класса:
Example::BLUE Example::Structure::Flag
При реализации метода Method обращения к тем же именам могут быть проще:
void Example::Method() { Color x = BLUE; y = Structure::Flag; }
При попытке обратиться извне класса к атрибуту набора BLUE компилятор выдаст ошибку, поскольку имя BLUE определено только в контексте класса.
Отметим одну особенность типа enum. Его атрибуты как бы экспортируются во внешнюю область имен. Несмотря на наличие фигурных скобок, к атрибутам перечисленного типа Color не обязательно (хотя и не воспрещается) обращаться Color::BLUE.
Общие данные
Иногда необходимо, чтобы к одной переменной можно было обращаться из разных функций. Предположим, в нашей программе используется генератор случайных чисел. Мы хотим инициализировать его один раз, в начале выполнения программы, а затем обращаться к нему из разных частей программы. Рассмотрим несколько возможных реализаций.
Во-первых, определим класс RandomGenerator с двумя методами: Init, для инициализации генератора, и GetNumber — для получения следующего числа.
// // файл RandomGenerator.h // class RandomGenerator { public: RandomGenerator(); ~RandomGenerator(); void Init(unsigned long start); unsigned long GetNumber(); private: unsigned long previousNumber; }; // // файл RandomGenerator.cpp // #include "RandomGenerator.h" #include time.h void RandomGenerator::Init(unsigned long x) { previousNumber = x; } unsigned long RandomGenerator::GetNumber(void) { unsigned long ltime; // получить текущее время в секундах, // прошедших с полуночи 1 января 1970 года time(ltime); ltime = 16; ltime = 16; // взять младшие 16 битов previousNumber = previousNumber * ltime; return previousNumber; }
Первый вариант состоит в создании объекта класса RandomGenerator в функции main и передаче ссылки на него во все функции и методы, где он потребуется.
// файл main.cpp #include "RandomGenerator.h" main() { RandomGenerator rgen; rgen.Init(1000); fun1(rgen); . . . Class1 b(rgen); . . . fun2(rgen); } void fun1(RandomGenerator r) { unsigned long x = r.GetNumber(); . . . } // файл class.cpp #include "RandomGenerator.h" Class1::Class1(RandomGenerator r) { . . . } void fun2(RandomGenerator r) { unsigned long x = r.GetNumber(); . . . }
Поскольку функция main завершает работу программы, все необходимые условия выполнены: генератор случайных чисел создается в самом начале программы, все объекты и функции обращаются к одному и тому же генератору, и генератор уничтожается по завершении программы. Такой стиль программирования допустимо использовать только в том случае, если передавать ссылку на используемый экземпляр объекта требуется нечасто. В противном случае этот способ крайне неудобен. Передавать ссылку на один и тот же объект утомительно, к тому же это загромождает интерфейс классов.
Оператор определения контекста namespace
Несмотря на столь развитую систему областей видимости имен, иногда и ее недостаточно. В больших программах возможность возникновения конфликтов на глобальном уровне достаточно реальна. Имена всех классов верхнего уровня должны быть различны. Хорошо, если вся программа разрабатывается одним человеком. А если группой? Особенно при использовании готовых библиотек классов. Чтобы избежать конфликтов, обычно договариваются о системе имен классов. Договариваться о стиле имен всегда полезно, однако проблема остается, особенно в случае разработки классов, которыми будут пользоваться другие.
Одно из сравнительно поздних добавлений к языку Си++ – контексты, определяемые с помощью оператора namespace. Они позволяют заключить группу объявлений классов, переменных и функций в отдельный контекст со своим именем. Предположим, мы разработали набор классов для вычисления различных математических функций. Все эти классы, константы и функции можно заключить в контекст math для того, чтобы, разрабатывая программу, использующую наши классы, другой программист не должен был бы выбирать имена, обязательно отличные от тех, что мы использовали.
namespace math { double const pi = 3.1415; double sqrt(double x); class Complex { public: . . . }; };
Теперь к константе pi следует обращаться math::pi.
Контекст может содержать как объявления, так и определения переменных, функций и классов. Если функция или метод определяется вне контекста, ее имя должно быть полностью квалифицировано
double math::sqrt(double x) { . . . }
Контексты могут быть вложенными, соответственно, имя должно быть квалифицировано несколько раз:
namespace first { int i; namespace second // первый контекст
// второй контекст { int i; int whati() { return first::i; } // возвращается значение первого i int anotherwhat { return i; } // возвращается значение второго i
} first::second::whati(); // вызов функции
Если в каком-либо участке программы интенсивно используется определенный контекст, и все имена уникальны по отношению к нему, можно сократить полные имена, объявив контекст текущим с помощью оператора using.
Повышение надежности обращения к общим данным
Определять глобальную переменную намного удобнее, чем передавать ссылку на генератор случайных чисел в каждый метод и функцию в качестве аргумента. Достаточно описать внешнюю глобальную переменную (включив соответствующий файл заголовков с помощью оператора #include), и генератор становится доступен. Не нужно менять интерфейс, если вдруг понадобится обратиться к генератору. Не следует передавать один и тот же объект в разные функции.
Тем не менее, использование глобальных переменных может привести к ошибкам. В нашем случае с генератором при его использовании нужно твердо помнить, что глобальная переменная уже определена. Простая забывчивость может привести к тому, что будет определен второй объект – генератор случайных чисел, например с именем randomGen. Поскольку с точки зрения правил языка никаких ошибок допущено не было, компиляция пройдет нормально. Однако результат работы программы будет не тот, которого мы ожидаем. (Исходя из определения класса, ответьте, почему).
При составлении программ самым лучшим решением будет то, которое не позволит ошибиться, т.е. неправильная программа не будет компилироваться. Не всегда это возможно, но в данном случае, как и во многих других, соответствующие средства имеются в языке Си++.
Изменим описание класса RandomGenerator:
class RandomGenerator { public: static void Init(unsigned long start); static unsigned long GetNumber(void); private: static unsigned long previousNumber; };
Определения методов Init и GetNumber не изменятся. Единственное, что надо будет добавить в файл RandomGenerator.cpp, это определение переменной previousNumber:
// // файл RandomGenerator.cpp // #include "RandomGenerator.h" #include time.h unsigned long RandomGenerator::previousNumber; . . .
Методы и атрибуты класса, описанные static, существуют независимо от объектов этого класса. Вызов статического метода имеет вид имя_класса::имя_метода, например RandomGenerator::Init(x). У статического метода не существует указателя this, таким образом, он имеет доступ либо к статическим атрибутам класса, либо к атрибутам передаваемых ему в качестве аргументов объектов. Например:
Исключительные ситуации
В языке Си++ реализован специальный механизм для сообщения об ошибках – механизм исключительных ситуаций. Название, конечно же, наводит на мысль, что данный механизм предназначен, прежде всего, для оповещения об исключительных ситуациях, о которых мы говорили чуть ранее. Однако механизм исключительных ситуаций может применяться и для обработки плановых ошибок.
Исключительная ситуация возникает при выполнении оператора throw . В качестве аргумента throw задается любое значение. Это может быть значение одного из встроенных типов (число, строка символов и т.п.) или объект любого определенного в программе класса.
При возникновении исключительной ситуации выполнение текущей функции или метода немедленно прекращается, созданные к этому моменту автоматические переменные уничтожаются, и управление передается в точку, откуда была вызвана текущая функция или метод. В точке возврата создается та же самая исключительная ситуация, прекращается выполнение текущей функции или метода, уничтожаются автоматические переменные, и управление передается в точку, откуда была вызвана эта функция или метод. Происходит своего рода откат всех вызовов до тех пор, пока не завершится функция main и, соответственно, вся программа.
Предположим, из main была вызвана функция foo , которая вызвала метод Open , а он в свою очередь возбудил исключительную ситуацию:
class Database { public : void Open(const char*serverName); }; void Database::Open(const char*serverName) { if (connect(serverName)==false ) throw 2; } foo() { Database database; database.Open("db-server"); String y; ... } int main() { String x; foo(); return 1; }
В этом случае управление вернется в функцию foo , будет вызван деструктор объекта database , управление вернется в main , где будет вызван деструктор объекта x , и выполнение программы завершится. Таким образом, исключительные ситуации позволяют аварийно завершать программы с некоторыми возможностями очистки переменных.
В таком виде оператор throw используется для действительно исключительных ситуаций, которые практически никак не обрабатываются. Гораздо чаще даже исключительные ситуации требуется обрабатывать.
Обработка исключительных ситуаций
В программе можно объявить блок, в котором мы будем отслеживать исключительные ситуации с помощью операторов try и catch :
try { ... }catch (тип_исключительной_операции){ ... }
Если внутри блока try возникла исключительная ситуация, то она первым делом передается в оператор catch . Тип исключительной ситуации – это тип аргумента throw . Если тип исключительной ситуации совместим с типом аргумента catch , выполняется блок catch . Тип аргумента catch совместим, если он либо совпадает с типом ситуации, либо является одним из ее базовых типов. Если тип несовместим, то происходит описанный выше откат вызовов, до тех пор, пока либо не завершится программа, либо не встретится блок catch с подходящим типом аргумента.
В блоке catch происходит обработка исключительной ситуации.
foo() { Database database; int attempCount =0; again: try { database.Open("dbserver"); } catch (int x){ cerr "Ошибка соединения номер " x endl; if (++attemptCount 5) goto again; throw ; } String y; ... }
Ссылка на аргумент throw передается в блок catch . Этот блок гасит исключительную ситуацию. Во время обработки в блоке catch можно создать либо ту же самую исключительную ситуацию с помощью оператора throw без аргументов, либо другую, или же не создавать никакой. В последнем случае исключительная ситуация считается погашенной, и выполнение программы продолжается после блока catch .
С одним блоком try может быть связано несколько блоков catch с разными аргументами. В этом случае исключительная ситуация последовательно "примеряется" к каждому catch до тех пор, пока аргумент не окажется совместимым. Этот блок и выполняется. Специальный вид catch
catch (...)
совместим с любым типом исключительной ситуации. Правда, в него нельзя передать аргумент.
Примеры обработки исключительных ситуаций
Механизм исключительных ситуаций предоставляет гибкие возможности для обработки ошибок, однако им надо уметь правильно пользоваться. В этом параграфе мы рассмотрим некоторые приемы обработки исключительных ситуаций.
Прежде всего, имеет смысл определить для них специальный класс. Простейшим вариантом является класс, который может хранить код ошибки:
class Exception { public : enum ErrorCode { NO_MEMORY, DATABASE_ERROR, INTERNAL_ERROR, ILLEGAL_VALUE }; Exception(ErrorCode errorKind, const StringerrMessage); ErrorCode GetErrorKind(void )const {return kind;}; const StringGetErrorMessage(void )const {return msg;}; private : ErrorCode kind; String msg; };
Создание исключительной ситуации будет выглядеть следующим образом:
if (connect(serverName)==false ) throw Exception(Exception::DATABASE_ERROR, serverName);
А проверка на исключительную ситуацию так:
try { ... }catch (Exceptione){ cerr "Произошла ошибка "e.GetErrorKind() "Дополнительная информация:" e.GetErrorMessage(); }
Преимущества класса перед просто целым числом состоят, во-первых, в том, что передается дополнительная информация и, во-вторых, в операторах catch можно реагировать только на ошибки определенного вида. Если была создана исключительная ситуация другого типа, например
throw AnotherException;
то блок catch будет пропущен: он ожидает только исключительных ситуаций типа Exception . Это особенно существенно при сопряжении нескольких различных программ и библиотек – каждый набор классов отвечает только за собственные ошибки.
В данном случае код ошибки записывается в объекте типа Exception . Если в одном блоке catch ожидается несколько разных исключительных ситуаций, и для них необходима разная обработка, то в программе придется анализировать код ошибки с помощью операторов if или switch .
try { ... }catch (Exceptione){ cerr "Произошла ошибка "e.GetErrorKind() "Дополнительная информация:" e.GetErrorMessage(); if (e.GetErrorKind()==Exception::NO_MEMORY || e.GetErrorKind()== Exception::INTERNAL_ERROR) throw ; else if (e.GetErrorKind()== Exception::DATABASE_ERROR) return TRY_AGAIN; else if (e.GetErrorKind()== Exception::ILLEGAL_VALUE) return NEXT_VALUE; }
Другим методом разделения различных исключительных ситуаций является создание иерархии классов – по классу на каждый тип исключительной ситуации.
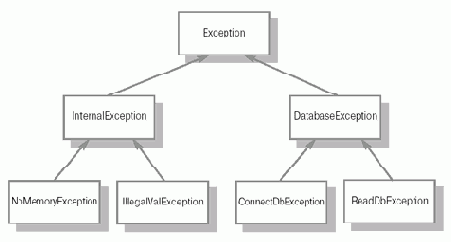
16.1. Пример иерархии классов для представления исключительных ситуаций.
В приведенной на рисунке 16.1 структуре классов все исключительные ситуации делятся на ситуации, связанные с работой базы данных (класс DatabaseException ), и внутренние ошибки программы (класс InternalException ). В свою очередь, ошибки базы данных бывают двух типов: ошибки соединения (представленные классом ConnectDbException ) и ошибки чтения (ReadDbException ). Внутренние исключительные ситуации и разделены на нехватку памяти (NoMemoryException )и недопустимые значения (IllegalValException ).
Теперь блок catch может быть записан в следующем виде:
try { }catch (ConnectDbExceptione ){ //обработка ошибки соединения с базой данных }catch (ReadDbExceptione){ //обработка ошибок чтения из базы данных }catch (DatabaseExceptione){ //обработка других ошибок базы данных }catch (NoMemoryExceptione){ //обработка нехватки памяти }catch (…){ //обработка всех остальных исключительных //ситуаций }
Напомним, что когда при проверке исключительной ситуации на соответствие аргументу оператора catch проверка идет последовательно до тех пор, пока не найдется подходящий тип. Поэтому, например, нельзя ставить catch для класса DatabaseException впереди catch для класса ConnectDbException – исключительная ситуация типа ConnectDbException совместима с классом DatabaseException (это ее базовый класс), и она будет обработана в catch для DatabaseException и не дойдет до блока с ConnectDbException .
Построение системы классов для разных исключительных ситуаций на стадии описания ошибок – процесс более трудоемкий, приходится создавать новый класс для каждого типа исключительной ситуации. Однако с точки зрения обработки он более гибкий и позволяет писать более простые программы.
Чтобы облегчить обработку ошибок и сделать запись о них более наглядной, описания методов и функций можно дополнить информацией, какого типа исключительные ситуации они могут создавать:
class Database { public : Open(const char*serverName) throw ConnectDbException; };
Такое описание говорит о том, что метод Open класса Database может создать исключительную ситуацию типа ConnectDbException . Соответственно, при использовании этого метода желательно предусмотреть обработку возможной исключительной ситуации.
В заключение приведем несколько рекомендаций по использованию исключительных ситуаций.
При возникновении исключительной ситуации остаток функции или метода не выполняется. Более того, при обработке ее не всегда известно, где именно возникла исключительная ситуация. Поэтому прежде чем выполнить оператор throw , освободите ресурсы, зарезервированные в текущей функции. Например, если какой-либо объект был создан с помощью new , необходимо явно вызвать для него delete .Избегайте использования исключительных ситуаций в деструкторах. Деструктор может быть вызван в результате уже возникшей исключительной ситуации при откате вызовов функций и методов. Повторная исключительная ситуация не обрабатывается и завершает выполнение программы.
Если исключительная ситуация возникла в конструкторе объекта, считается, что объект сформирован не полностью, и деструктор для него вызван не будет.
Виды ошибок
Существенной частью любой программы является обработка ошибок. Прежде чем перейти к описанию средств языка Си++, предназначенных для обработки ошибок, остановимся немного на том,какие, собственно, ошибки мы будем рассматривать.
Ошибки компиляции пропустим:пока все они не исправлены, программа не готова, и запустить ее нельзя. Здесь мы будем рассматривать только ошибки, происходящие во время выполнения программы.
Первый вид ошибок, который всегда приходит в голову – это ошибки программирования. Сюда относятся ошибки в алгоритме, в логике программы и чисто программистские ошибки. Ряд возможных ошибок мы называли ранее (например, при работе с указателями), но гораздо больше вы узнаете на собственном горьком опыте.
Теоретически возможно написать программу без таких ошибок. Во многом язык Си++ помогает предотвратить ошибки во время выполнения программы,осуществляя строгий контроль на стадии компиляции. Вообще, чем строже контроль на стадии компиляции, тем меньше ошибок остается при выполнении программы.
Перечислим некоторые средства языка, которые помогут избежать ошибок:
Контроль типов. Случаи использования недопустимых операций и смешения несовместимых типов будут обнаружены компилятором. Обязательное объявление имен до их использования. Невозможно вызвать функцию с неверным числом аргументов. При изменении определения переменной или функции легко обнаружить все места, где она используется. Ограничение видимости имен, контексты имен. Уменьшается возможность конфликтов имен, неправильного переопределения имен.
Самым важным средством уменьшения вероятности ошибок является объектно-ориентированный подход к программированию,который поддерживает язык Си++. Наряду с преимуществами объектного программирования, о которых мы говорили ранее, построение программы из классов позволяет отлаживать классы по отдельности и строить программы из надежных составных "кирпичиков", используя одни и те же классы многократно.
Несмотря на все эти положительные качества языка, остается "простор" для написания ошибочных программ. По мере рассмотрения свойств языка, мы стараемся давать рекомендации, какие возможности использовать, чтобы уменьшить вероятность ошибки.
Лучше исходить из того, что идеальных программ не существует, это помогает разрабатывать более надежные программы. Самое главное – обеспечить контроль данных, а для этого необходимо проверять в программе все, что может содержать ошибку. Если в программе предполагается какое-то условие, желательно проверить его, хотя бы в начальной версии программы, до того, как можно будет на опыте убедиться, что это условие действительно выполняется. Важно также проверять указатели, передаваемые в качестве аргументов, на равенство нулю; проверять, не выходят ли индексы за границы массива и т.п.
Ну и решающими качествами, позволяющими уменьшить количество ошибок, являются внимательность, аккуратность и опыт.
Второй вид ошибок – "предусмотренные", запланированные ошибки. Если разрабатывается программа диалога с пользователем, такая программа обязана адекватно реагировать и обрабатывать неправильные нажатия клавиш. Программа чтения текста должна учитывать возможные синтаксические ошибки. Программа передачи данных по телефонной линии должна обрабатывать помехи и возможные сбои при передаче. Такие ошибки – это, вообще говоря, не ошибки с точки зрения программы, а плановые ситуации, которые она обрабатывает.
Третий вид ошибок тоже в какой-то мере предусмотрен. Это исключительные ситуации, которые могут иметь место, даже если в программе нет ошибок. Например, нехватка памяти для создания нового объекта. Или сбой диска при извлечении информации из базы данных.
Именно обработка двух последних видов ошибок и рассматривается в последующих разделах. Граница между ними довольно условна. Например, для большинства программ сбой диска – исключительная ситуация, но для операционной системы сбой диска должен быть предусмотрен и должен обрабатываться. Скорее два типа можно разграничить по тому, какая реакция программы должна быть предусмотрена. Если после плановых ошибок программа должна продолжать работать, то после исключительных ситуаций надо лишь сохранить уже вычисленные данные и завершить программу.
Возвращаемое значение как признак ошибки
Простейший способ сообщения об ошибках предполагает использование возвращаемого значения функции или метода. Функция сохранения объекта в базе данных может возвращать логическое значение: true в случае успешного сохранения, false – в случае ошибки.
class Database { public: bool SaveObject(const Objectobj); };
Соответственно, вызов метода должен выглядеть так:
if (database.SaveObject(my_obj) == false ){ //обработка ошибки }
Обработка ошибки, разумеется, зависит от конкретной программы. Типична ситуация, когда при многократно вложенных вызовах функций обработка происходит на несколько уровней выше, чем уровень, где ошибка произошла. В таком случае результат, сигнализирующий об ошибке, придется передавать во всех вложенных вызовах.
int main() { if (fun1()==false ) //обработка ошибки return 1; } bool fun1() { if (fun2()==false ) return false ; return true ; } bool fun2() { if (database.SaveObject(obj)==false ) return false ; return true ; }
Если функция или метод должны возвращать какую-то величину в качестве результата, то особое, недопустимое, значение этой величины используется в качестве признака ошибки. Если метод возвращает указатель, выдача нулевого указателя применяется в качестве признака ошибки. Если функция вычисляет положительное число, возврат - 1 можно использовать в качестве признака ошибки.
Иногда невозможно вернуть признак ошибки в качестве возвращаемого значения. Примером является конструктор объекта, который не может вернуть значение. Как же сообщить о том, что во время инициализации объекта что-то было не так?
Распространенным решением является дополнительный атрибут объекта – флаг, отражающий состояние объекта. Предположим, конструктор класса Database должен соединиться с сервером базы данных.
class Database { public : Database(const char *serverName); ... bool Ok(void )const {return okFlag;}; private : bool okFlag; }; Database::Database(const char*serverName) { if (connect(serverName)==true ) okFlag =true ; else okFlag =false ; } int main() { Database database("db-server"); if (!database.Ok()){ cerr "Ошибка соединения с базой данных"endl; return 0; } return 1; }
Лучше вместо метода Ok, возвращающего
Лучше вместо метода Ok, возвращающего значение флага okFlag, переопределить операцию ! (отрицание).
class Database { public : bool operator !()const {return !okFlag;}; };
Тогда проверка успешности соединения с базой данных будет выглядеть так:
if (!database){ cerr "Ошибка соединения с базой данных"endl; }
Следует отметить, что лучше избегать такого построения классов, при котором возможны ошибки в конструкторе. Из конструктора можно выделить соединение с сервером базы данных в отдельный метод Open :
class Database { public : Database(); bool Open(const char*serverName); }
и тогда отпадает необходимость в операции ! или методе Ok().
Использование возвращаемого значения в качестве признака ошибки – метод почти универсальный. Он применяется, прежде всего, для обработки запланированных ошибочных ситуаций. Этот метод имеет ряд недостатков. Во-первых, приходится передавать признак ошибки через вложенные вызовы функций. Во-вторых, возникают неудобства, если метод или функция уже возвращают значение, и приходится либо модифицировать интерфейс, либо придумывать специальное "ошибочное" значение. В-третьих, логика программы оказывается запутанной из-за сплошных условных операторов if с проверкой на ошибочное значение.
on_load_lecture()

/p> |
/p> |
/p> |
вопросы |
учебники
|
для печати и PDA
|
Курсы | Учебные программы | Учебники | Новости | Форум | Помощь Телефон: +7 (495) 253-9312, 253-9313, факс: +7 (495) 253-9310, email: info@intuit.ru 2003-2007, INTUIT.ru::Интернет-Университет Информационных Технологий - дистанционное образование |
Манипуляторы и форматирование ввода-вывода
Часто бывает необходимо вывести строку или число в определенном формате. Для этого используются так называемые манипуляторы.
Манипуляторы – это объекты особых типов, которые управляют тем, как ostream или istream обрабатывают последующие аргументы. Некоторые манипуляторы могут также выводить или вводить специальные символы.
С одним манипулятором мы уже сталкивались, это endl. Он вызывает вывод символа новой строки. Другие манипуляторы позволяют задавать формат вывода чисел:
|
endl | при выводе перейти на новую строку; |
|
ends | вывести нулевой байт (признак конца строки символов); |
|
flush | немедленно вывести и опустошить все промежуточные буферы; |
|
dec | выводить числа в десятичной системе (действует по умолчанию); |
|
oct | выводить числа в восьмеричной системе; |
|
hex | выводить числа в шестнадцатиричной системе счисления; |
|
setw (int n) | установить ширину поля вывода в n символов (n – целое число); |
|
setfill(int n) | установить символ-заполнитель; этим символом выводимое значение будет дополняться до необходимой ширины; |
|
setprecision(int n) | установить количество цифр после запятой при выводе вещественных чисел; |
|
setbase(int n) | установить систему счисления для вывода чисел; n может принимать значения 0, 2, 8, 10, 16, причем 0 означает систему счисления по умолчанию, т.е. 10. |
Использовать манипуляторы просто – их надо вывести в выходной поток. Предположим, мы хотим вывести одно и то же число в разных системах счисления:
int x = 53; cout "Десятичный вид: " dec x endl "Восьмиричный вид: " oct x endl "Шестнадцатиричный вид: " hex x endl
Аналогично используются манипуляторы с параметрами. Вывод числа с разным количеством цифр после запятой:
double x; // вывести число в поле общей шириной // 6 символов (3 цифры до запятой, // десятичная точка и 2 цифры после запятой) cout setw(6) setprecision(2) x endl;
Те же манипуляторы (за исключением endl и ends могут использоваться и при вводе. В этом случае они описывают представление вводимых чисел. Кроме того, имеется манипулятор, работающий только при вводе, это ws. Данный манипулятор переключает вводимый поток в такой режим, при котором все пробелы (включая табуляцию, переводы строки, переводы каретки и переводы страницы) будут вводиться. По умолчанию эти символы воспринимаются как разделители между атрибутами ввода.
int x; // ввести шестнадцатиричное число cin hex x;
Операции и для потоков
В классах iostream операции и определены для всех встроенных типов языка Си++ и для строк (тип char*). Если мы хотим использовать такую же запись для ввода и вывода других классов, определенных в программе, для них нужно определить эти операции.
class String { public: friend ostream operator(ostream os, const String s); friend istream operator(istream is, String s); private: char* str; int length; }; ostream operator(ostream os, const String s) { os s.str; return os; } istream operator(istream is, String s) { // предполагается, что строк длиной более // 1024 байтов не будет char tmp[1024]; is tmp;
if (str != 0) { delete [] str; } length = strlen(tmp); str = new char[length + 1]; if (str == 0) { // обработка ошибок length = 0; return is; } strcpy(str, tmp); return is; }
Как показано в примере класса String, операция , во-первых, является не методом класса String, а отдельной функцией. Она и не может быть методом класса String, поскольку ее правый операнд – объект класса ostream. С точки зрения записи, она могла бы быть методом класса ostream, но тогда с добавлением нового класса приходилось бы модифицировать класс ostream, что невозможно – каждый бы модифицировал стандартные классы, поставляемые вместе с компилятором. Когда же операция реализована как отдельная функция, достаточно в каждом новом классе определить ее, и можно использовать запись:
String x; . . . cout "this is a string: " x;
Во-вторых, операция возвращает в качестве результата ссылку на поток вывода. Это позволяет использовать ее в выражениях типа приведенного выше, соединяющих несколько операций вывода в одно выражение.
Аналогично реализована операция ввода. Для класса istream она определена для всех встроенных типов языка Си++ и указателей на строку символов. Если необходимо, чтобы класс, определенный в программе, позволял ввод из потока, для него нужно определить операцию в качестве функции friend.
Потоки
Механизм для ввода-вывода в Си++ называется потоком. Название произошло от того,что информация вводится и выводится в виде потока байтов – символ за символом.
Класс istream реализует поток ввода, класс ostream – поток вывода. Эти классы определены в файле заголовков iostream.h. Библиотека потоков ввода-вывода определяет три глобальных объекта: cout,cin и cerr. cout называется стандартным выводом, cin – стандартным вводом, cerr – стандартным потоком сообщений об ошибках. cout и cerr выводят на терминал и принадлежат к классу ostream, cin имеет тип istream и вводит с терминала. Разница между cout и cerr существенна в Unix – они используют разные дескрипторы для вывода. В других системах они существуют больше для совместимости.
Вывод осуществляется с помощью операции , ввод с помощью операции . Выражение
cout "Пример вывода: " 34;
напечатает на терминале строку "Пример вывода", за которым будет выведено число 34. Выражение
int x; cin x;
введет целое число с терминала в переменную x. (Разумеется, для того, чтобы ввод произошел, на терминале нужно напечатать какое-либо число и нажать клавишу возврат каретки.)
Строковые потоки
Специальным случаем потоков являются строковые потоки, представленные классом strstream. Отличие этих потоков состоит в том, что все операции происходят в памяти. Фактически такие потоки формируют форматированную строку символов, заканчивающуюся нулевым байтом. Строковые потоки применяются, прежде всего, для того, чтобы облегчить форматирование данных в памяти.
Например, в приведенном в предыдущей главе классе Exception для исключительной ситуации можно добавить сообщение. Если мы хотим составить сообщение из нескольких частей, то может возникнуть необходимость форматирования этого сообщения:
// произошла ошибка strstream ss; ss "Ошибка ввода-вывода, регистр: " oct reg1; ss "Системная ошибка номер: " dec errno ends; String msg(ss.str()); ss.rdbuf()-freeze(0); Exception ex(Exception::INTERNAL_ERROR, msg); throw ex;
Сначала создается объект типа strstream с именем ss. Затем в созданный строковый поток выводятся сформатированные нужным образом данные. Отметим, что в конце мы вывели манипулятор ends, который добавил необходимый для символьной строки байтов нулевой байт. Метод str() класса strstream предоставляет доступ к сформатированной строке (тип его возвращаемого значения – char*). Следующая строка освобождает память, занимаемую строковым потоком (подробнее об этом рассказано ниже). Последние две строки создают объект типа Exception с типом ошибки INTERNAL_ERROR и сформированным сообщением и вызывают исключительную ситуацию.
Важное свойство класса strstream состоит в том, что он автоматически выделяет нужное количество памяти для хранения строк. В следующем примере функция split_numbers выделяет числа из строки, состоящей из нескольких чисел, разделенных пробелом, и печатает их по одному на строке.
#include strstream.h void split_numbers(const char* s) { strstream iostr; iostr s ends; int x; while (iostr x) cout x endl; } int main() { split_numbers("123 34 56 932"); return 1; }
Замечание. В среде Visual C++ файл заголовков называется strstream.h.
Как видно из этого примера, независимо от того, какова на самом деле длина входной строки, объект iostr автоматически выделяет память, и при выходе из функции split_numbers, когда объект уничтожается, память будет освобождена.
Однако из данного правила есть одно исключение. Если программа обращается непосредственно к хранимой в объекте строке с помощью метода str (), то объект перестает контролировать эту память, а это означает, что при уничтожении объекта память не будет освобождена. Для того чтобы память все-таки была освобождена, необходимо вызвать метод rdbuf()-freeze(0) (см. предыдущий пример).
Ввод-вывод файлов
Ввод-вывод файлов может выполняться как с помощью стандартных функций библиотеки Си, так и с помощью потоков ввода-вывода. Функции библиотеки Си являются функциями низкого уровня, без всякого контроля типов.
Прежде чем перейти к рассмотрению собственно классов, остановимся на том, как осуществляются операции ввода-вывода с файлами. Файл рассматривается как последовательность байтов. Чтение или запись выполняются последовательно. Например, при чтении мы начинаем с начала файла. Предположим, первая операция чтения ввела 4 байта, интерпретированные как целое число. Тогда следующая операция чтения начнет ввод с пятого байта, и так далее до конца файла.
Аналогично происходит запись в файл – по умолчанию первая запись производится в конец имеющегося файла, а все последующие операции записи последовательно пишут данные друг за другом. При операциях чтения-записи говорят, что существует текущая позиция, начиная с которой будет производиться следующая операция.
Большинство файлов обладают возможностью прямого доступа. Это означает, что можно производить операции ввода-вывода не последовательно, а в произвольном порядке: после чтения первых 4-х байтов прочесть с 20 по 30, затем два последних и т.п. При написании программ на языке Си++ возможность прямого доступа обеспечивается тем, что текущую позицию чтения или записи можно установить явно.
В библиотеке Си++ для ввода-вывода файлов существуют классы ofstream (вывод) и ifstream (ввод). Оба они выведены из класса fstream. Сами операции ввода-вывода выполняются так же, как и для других потоков – операции и определены для класса fstream как "ввести" и "вывести" соответствующее значение. Различия заключаются в том, как создаются объекты и как они привязываются к нужным файлам.
При выводе информации в файл первым делом нужно определить, в какой файл будет производиться вывод. Для этого можно использовать конструктор класса ofstream в виде:
ofstream(const char* szName, int nMode = ios::out, int nProt = filebuf::openprot);
Первый аргумент – имя выходного файла, и это единственный обязательный аргумент. Второй аргумент задает режим, в котором открывается поток. Этот аргумент – битовое ИЛИ следующих величин:
ios::app | при записи данные добавляются в конец файла, даже если текущая позиция была перед этим перемещена; |
ios::ate | при создании потока текущая позиция помещается в конец файла; однако, в отличие от режима app, запись ведется в текущую позицию; |
ios::in | поток создается для ввода; если файл уже существует, он сохраняется; |
ios::out | поток создается для вывода (режим по умолчанию); |
ios::trunc | если файл уже существует, его прежнее содержимое уничтожается, и длина файла становится равной нулю; режим действует по умолчанию, если не заданы ios::ate, ios::app или ios::in; |
ios::binary | ввод-вывод будет происходить в двоичном виде, по умолчанию используется текстовое представление данных. |
Можно создать поток вывода с помощью стандартного конструктора без аргументов, а позднее выполнить метод open с такими же аргументами, как у предыдущего конструктора:
void open(const char* szName, int nMode = ios::out, int nProt = filebuf::openprot);
Только после того, как поток создан и соединен с определенным файлом (либо с помощью конструктора с аргументами, либо с помощью метода open), можно выполнять вывод. Выводятся данные операцией . Кроме того, данные можно вывести с помощью методов write или put:
ostream write(const char* pch, int nCount); ostream put(char ch);
Метод write выводит указанное количество байтов (nCount), расположенных в памяти, начиная с адреса pch. Метод put выводит один байт.
Для того чтобы переместить текущую позицию, используется метод seekp:
ostream seekp(streamoff off, ios::seek_dir dir);
Первый аргумент – целое число, смещение позиции в байтах. Второй аргумент определяет, откуда отсчитывается смещение; он может принимать одно из трех значений:
ios::beg | смещение от начала файла |
ios::cur | смещение от текущей позиции |
ios::end | смещение от конца файла |
/p> Сместив текущую позицию, операции вывода продолжаются с нового места файла.
После завершения вывода можно выполнить метод close, который выводит внутренние буферы в файл и отсоединяет поток от файла. То же самое происходит и при уничтожении объекта.
Класс ifstream, осуществляющий ввод из файлов, работает аналогично. При создании объекта типа ifstream в качестве аргумента конструктора можно задать имя существующего файла:
ifstream(const char* szName, int nMode = ios::in, int nProt = filebuf::openprot);
Можно воспользоваться стандартным конструктором, а подсоединиться к файлу с помощью метода open.
Чтение из файла производится операцией или методами read или get:
istream read(char* pch, int nCount); istream get(char rch);
Метод read вводит указанное количество байтов (nCount) в память, начиная с адреса pch. Метод get вводит один байт.
Так же, как и для вывода, текущую позицию ввода можно изменить с помощью метода seekp, а по завершении выполнения операций закрыть файл с помощью close или просто уничтожить объект.
Функции-шаблоны
Запишем алгоритм поиска минимума двух величин, где в качестве параметра используется тип этих величин.
template class T const T min(const T a, const T b) { if (a b) return a; else return b; }
Данная запись еще не создала ни одной функции, это лишь шаблон для определенной функции. Только тогда, когда происходит обращение к функции с аргументами конкретного типа, будет выполнена генерация конкретной функции.
int x, y, z; String s1, s2, s3; . . . // генерация функции min для класса String s1 = min(s2, s3); . . . // генерация функции min для типа int x = min(y, z);
Первое обращение к функции min генерирует функцию
const String min(const String a, const String b);
Второе обращение генерирует функцию
const int min(const int a, const int b);
Объявление шаблона функции min говорит о том, что конкретная функция зависит от одного параметра – типа T. Первое обращение к min в программе использует аргументы типа String. В шаблон функции подставляется тип String вместо T. Получается функция:
const String min(const String a, const String b) { if (a b) return a; else return b; }
Эта функция компилируется и используется в программе. Аналогичные действия выполняются и при втором обращении, только теперь вместо параметра T подставляется тип int. Как видно из приведенных примеров, компилятор сам определяет, какую функцию надо использовать, и автоматически генерирует необходимое определение.
У функции-шаблона может быть несколько параметров. Так, например, функция find библиотеки STL (стандартной библиотеки шаблонов), которая ищет первый элемент, равный заданному, в интервале значений, имеет вид:
template class InIterator, class T InIterator find(InIterator first, InIterator last, const T val);
Класс T – это тип элементов интервала. Тип InIterator – тип указателя на его начало и конец.
"Интеллигентный указатель"
Рассмотрим еще один пример использования класса-шаблона. С его помощью мы попытаемся " усовершенствовать" указатели языка Си++. Если указатель указывает на объект, выделенный с помощью операции new, необходимо явно вызывать операцию delete тогда, когда объект становится не нужен. Однако далеко не всегда просто определить, нужен объект или нет, особенно если на него могут ссылаться несколько разных указателей. Разработаем класс, который ведет себя очень похоже на указатель, но автоматически уничтожает объект, когда уничтожается последняя ссылка на него. Назовем этот класс "интеллигентный указатель" (Smart Pointer). Идея заключается в том, что настоящий указатель мы окружим специальной оболочкой. Вместе со значением указателя мы будем хранить счетчик – сколько других объектов на него ссылается. Как только значение этого счетчика станет равным нулю, объект, на который указатель указывает, пора уничтожать.
Структура Ref хранит исходный указатель и счетчик ссылок.
template class T struct Ref { T* realPtr; int counter; };
Теперь определим интерфейс "интеллигентного указателя":
template class T class SmartPtr { public: // конструктор из обычного указателя SmartPtr(T* ptr = 0); // копирующий конструктор SmartPtr(const SmartPtr s); ~SmartPtr(); SmartPtr operator=(const SmartPtr s); SmartPtr operator=(T* ptr); T* operator-() const; T operator*() const; private: RefT* refPtr; };
У класса SmartPtr определены операции обращения к элементу -, взятия по адресу "*" и операции присваивания. С объектом класса SmartPtr можно обращаться практически так же, как с обычным указателем.
struct A { int x; int y; }; SmartPtrA aPtr(new A); int x1 = aPtr-x; (*aPtr).y = 3;
// создать новый указатель // обратиться к элементу A // обратиться по адресу
Рассмотрим реализацию методов класса SmartPtr. Конструктор инициализирует объект указателем. Если указатель равен нулю, то refPtr устанавливается в ноль. Если же конструктору передается ненулевой указатель, то создается структура Ref, счетчик обращений в которой устанавливается в 1, а указатель – в переданный указатель:
template class T SmartPtrT::SmartPtr(T* ptr) { if (ptr == 0) refPtr = 0; else { refPtr = new RefT; refPtr-realPtr = ptr; refPtr-counter = 1; } }
Деструктор уменьшает количество ссылок на 1 и, если оно достигло 0, уничтожает объект
template class T SmartPtr T::~SmartPtr() { if (refPtr != 0) { refPtr-counter--; if (refPtr-counter = 0) { delete refPtr-realPtr; delete refPtr; } } }
Реализация операций - и * довольно проста:
template class T T* SmartPtrT::operator-() const { if (refPtr != 0) return refPtr-realPtr; else return 0; } template class T T SmartPtrT::operator*() const { if (refPtr != 0) return *refPtr-realPtr; else throw bad_pointer; }
Самые сложные для реализации – копирующий конструктор и операции присваивания. При создании объекта SmartPtr – копии имеющегося – мы не будем копировать сам исходный объект. Новый "интеллигентный указатель" будет ссылаться на тот же объект, мы лишь увеличим счетчик ссылок.
template class T SmartPtrT::SmartPtr(const SmartPtr s):refPtr(s.refPtr) { if (refPtr != 0) refPtr-counter++; }
При выполнении присваивания, прежде всего, нужно отсоединиться от имеющегося объекта, а затем присоединиться к новому, подобно тому, как это сделано в копирующем конструкторе.
template class T SmartPtr SmartPtrT::operator=(const SmartPtr s) { // отсоединиться от имеющегося указателя if (refPtr != 0) { refPtr-counter--; if (refPtr-counter = 0) { delete refPtr-realPtr; delete refPtr; } } // присоединиться к новому указателю refPtr = s.refPtr; if (refPtr != 0) refPtr-counter++; }
В следующей функции при ее завершении объект класса Complex будет уничтожен:
void foo(void) { SmartPtrComplex complex(new Complex); SmartPtrComplex ptr = complex; return; }
Назначение шаблонов
Алгоритм выполнения какого-либо действия можно записывать независимо от того, какого типа данные обрабатываются. Простейшим примером служит определение минимума из двух величин.
if (a b) x = a; else x = b;
Независимо от того, к какому именно типу принадлежат переменные a, b и x, если это один и тот же тип, для которого определена операция "меньше", запись будет одна и та же. Было бы естественно определить функцию min, возвращающую минимум из двух своих аргументов. Возникает вопрос, как описать аргументы этой функции? Конечно, можно определить min для всех известных типов, однако, во-первых, пришлось бы повторять одну и ту же запись многократно, а во-вторых, с добавлением новых классов добавлять новые функции.
Аналогичная ситуация встречается и в случае со многими сложными структурами данных. В классе, реализующем связанный список целых чисел, алгоритмы добавления нового атрибута списка, поиска нужного атрибута и так далее не зависят от того, что атрибуты списка – целые числа. Точно такие же алгоритмы нужно будет реализовать для списка вещественных чисел или указателей на класс Book.
Механизм шаблонов в языке Си++ позволяет эффективно решать многие подобные задачи.
Шаблоны классов
Шаблон класса имеет вид:
template список параметров class объявление_класса
Список параметров класса-шаблона аналогичен списку параметров функции-шаблона: список классов и переменных, которые подставляются в объявление класса при генерации конкретного класса.
Очень часто шаблоны используются для создания коллекций, т.е. классов, которые представляют собой набор объектов одного и того же типа. Простейшим примером коллекции может служить массив. Массив, несомненно, очень удобная структура данных, однако у него имеется ряд существенных недостатков, к которым, например, относятся необходимость задавать размер массива при его определении и отсутствие контроля использования значений индексов при обращении к атрибутам массива.
Попробуем при помощи шаблонов устранить два отмеченных недостатка у одномерного массива. При этом по возможности попытаемся сохранить синтаксис обращения к атрибутам массива. Назовем новую структуру данных вектор vector.
template class T class vector { public: vector() : nItem(0), items(0) {}; ~vector() { delete items; }; void insert(const T t) { T* tmp = items; items = new T[nItem + 1]; memcpy(items, tmp, sizeof(T)* nItem); items[++nItem] = t; delete tmp; } void remove(void) { T* tmp = items; items = new T[--nItem]; memcpy(items, tmp, sizeof(T) * nItem); delete tmp; } const T operator[](int index) const { if ((index 0) || (index = nItem)) throw IndexOutOfRange; return items[index]; } T operator[](int index) { if ((index 0) || (index = nItem)) throw IndexOutOfRange; return items[index]; } private: T* items; int nItem; };
Кроме конструктора и деструктора, у нашего вектора есть только три метода: метод insert добавляет в конец вектора новый элемент, увеличивая длину вектора на единицу, метод remove удаляет последний элемент вектора, уменьшая его длину на единицу, и операция [] обращается к n-ому элементу вектора.
vectorint IntVector; IntVector.insert(2); IntVector.insert(3); IntVector.insert(25); // получили вектор из трех атрибутов: // 2, 3 и 25 // переменная x получает значение 3 int x = IntVector[1]; // произойдет исключительная ситуация int y = IntVector[4]; // изменить значение второго атрибута вектора. IntVector[1] = 5;
Обратите внимание, что операция [] определена в двух вариантах – как константный метод и как неконстантный. Если операция [] используется справа от операции присваивания (в первых двух присваиваниях), то используется ее константный вариант, если слева (в последнем присваивании) – неконстантный. Использование операции индексирования [] слева от операции присваивания означает, что значение объекта изменяется, соответственно, нужна неконстантная операция.
Параметр шаблона vector – любой тип, у которого определены операция присваивания и стандартный конструктор. (Стандартный конструктор необходим при операции new для массива.)
Так же, как и с функциями-шаблонами, при задании первого объекта типа vectorint автоматически происходит генерация конкретного класса из шаблона. Если далее в программе будет использоваться вектор вещественных чисел или строк, значит, будут сгенерированы конкретные классы и для них. Генерация конкретного класса означает, что генерируются все его методы, соответственно, размер исходного кода растет. Поэтому из небольшого шаблона может получиться большая программа. Ниже мы рассмотрим одну возможность сокращения размера программы, использующей почти однотипные шаблоны.
Сгенерировать конкретный класс из шаблона можно явно, записав:
template vectorint;
Этот оператор не создаст никаких объектов типа vectorint, но, тем не менее, вызовет генерацию класса со всеми его методами.
Задание свойств класса
Одним из методов использования шаблонов является уточнение поведения с помощью дополнительных параметров шаблона. Предположим, мы пишем функцию сортировки вектора:
template class T void sort_vector(vectorT vec) { for (int i = 0; i vec.size() -1; i++) for (int j = i; j vec.size(); j++) { if (vec[i] vec[j]) { T tmp = vec[i]; vec[i] = vec[j]; vec[j] = tmp; } } }
Эта функция будет хорошо работать с числами, но если мы захотим использовать ее для массива указателей на строки (char*), то результат будет несколько неожиданный. Сортировка будет выполняться не по значению строк, а по их адресам (операция "меньше" для двух указателей – это сравнение значений этих указателей, т.е. адресов величин, на которые они указывают, а не самих величин). Чтобы исправить данный недостаток, добавим к шаблону второй параметр:
template class T, class Compare void sort_vector(vectorT vec) { for (int i = 0; i vec.size() -1; i++) for (int j = i; j vec.size(); j++) { if (Compare::less(vec[i], vec[j])) { T tmp = vec[i]; vec[i] = vec[j]; vec[j] = tmp; } } }
Класс Compare должен реализовывать статическую функцию less, сравнивающую два значения типа T. Для целых чисел этот класс может выглядеть следующим образом:
class CompareInt { static bool less(int a, int b) { return a b; }; };
Сортировка вектора будет выглядеть так:
vectorint vec; sortint, CompareInt(vec);
Для указателей на байт (строк) можно создать класс
class CompareCharStr { static bool less(char* a, char* b) { return strcmp(a,b) = 0; } };
и, соответственно, сортировать с помощью вызова
vectorchar* svec; sortchar*, CompareCharStr(svec);
Как легко заметить, для всех типов, для которых операция "меньше" имеет нужный нам смысл, можно написать шаблон класса сравнения:
templateclass T Compare { static bool less(T a, T b) { return a b; }; };
и использовать его в сортировке (обратите внимание на пробел между закрывающимися угловыми скобками в параметрах шаблона; если его не поставить, компилятор спутает две скобки с операцией сдвига):
vectordouble dvec; sortdouble, Comparedouble (dvec);
Чтобы не загромождать запись, воспользуемся возможностью задать значение параметра по умолчанию. Так же, как и для аргументов функций и методов, для параметров шаблона можно определить значения по умолчанию. Окончательный вид функции сортировки будет следующий:
template class T, class C = CompareT void sort_vector(vectorT vec) { for (int i = 0; i vec.size() -1; i++) for (int j = i; j vec.size(); j++) { if (C::less(vec[i], vec[j])) { T tmp = vec[i]; vec[i] = vec[j]; vec[j] = tmp; } } }
Второй параметр шаблона иногда называют параметром-штрих, поскольку он лишь модифицирует поведение класса, который манипулирует типом, определяемым первым параметром.
